Team:Vilnius-Lithuania-OG/Design
In this section you will find out what is Catalytic Activity Sequencing (CAT-Seq). Firstly, the CAT-Seq is introduced in brief to give a quick overview of how the system works and what are the different parts it consists of. Next, every step of the system is described and illustrated in detail. Finally, we show how we have applied this design in order to build the proof of concept of CAT-Seq.
It should be noted that only the final form of the system design is described here. Yet, the design of a new method is a highly dynamic process which requires an immense amount of theoretical and practical iterations that closely follow the main principles of engineering. Therefore, in order to see the CAT-Seq system engineering story - how it began, how early designs have looked, how and why did the system design change during the whole project year and what influenced those changes - please head to the Human Practices section!
CAT-Seq allows to rapidly record the information about billions catalytic biomolecule activities in parallel. Each measured activity is then simultaneously written into DNA sequence encoding the particular biomolecule. After the recording, both the biomolecule sequence and it’s activity can be read using nanopore sequencing.
Currently, droplet microfluidics offer an efficient and high-throughput way to parallelise high number of reactions. As each molecule is encapsulated in a unique water droplet, various physically separated reactions can be carried out at the same time. Yet, what is missing, is a way to record the activity information in each droplet, so that after the droplets are collected together and broken, the sequence and function relationship is not lost. In other words, the main goal of CAT-Seq is to connect catalytic biomolecule’s phenotype to genotype in ultra-high throughput manner.
During the theoretical design phase it became apparent that recording such information in mutant’s own DNA sequence from which it was synthesized would be the smartest choice. That is because DNA already contains half of the information we want to save - the sequence that codes the biomolecule. As we want to associate the sequence information with the information of catalytic activity, there did not seem to be a better object than the DNA.
While navigating the vast sea of scientific literature we have stumbled upon a fact that some polymerases do not incorporate nucleotides into DNA sequence if they are modified. We have then come up with an idea to attach the enzyme substrate to the nucleotides and term this compound “Substrate nucleotide”.

Such modified nucleotides then act as a target for various catalytic biomolecules - they would first need to recognise it, bind to it and then chemically convert it, resulting in the removal of the substrate. We call this chemically converted nucleotide a “Product Nucleotide”.
The removal of the different substrates can be achieved by different types of catalytic biomolecules that catalyse a vast range of different chemical reactions. For example, all of the six major classes of enzymes can be used. To explore the prospects of recording the activities of different types of catalytic biomolecules, please head to the Substrate Design Prospects page!
The catalytic molecule acting on the substrate nucleotide is the main principle behind CAT-Seq. A substrate nucleotide cannot be incorporated by DNA polymerase. In contrast - Product Nucleotide can be incorporated.
Yet, such concept alone is not enough to record catalytic activities of the biomolecules. What else is needed? Let’s dive right in.
Every part of the CAT-Seq design page is divided in two main sections:
General description

A library of is prepared (1) for a specific or group of catalytic biomolecules - enzymes, catalytic RNAs or catalytic DNAs. For example, such library may consist of billions of randomly mutated enzyme sequences, a few computationally derived enzymes or a metagenomic enzyme library.
The next step, after building the library, is adding the essential genetic regulatory parts - RNA polymerase promoter and a ribosome binding site (2). These parts are necessary and sufficient to synthesize the biomolecules in both cells and in-vitro. For example, this can be done by ligating the regulatory parts onto DNA fragments or by using overhang PCR, which adds additional sequences to the end of your amplified product.
After the regulatory parts are added the fragments must then be circularized (3). DNA fragments are circularized for two main reasons:
1. First of all, in order to amplify the DNA inside microfluidic droplets an isothermal amplification reaction must be used. That is because droplets become highly unstable and can break easily when the temperature is quickly altered - just like during the popular polymerase chain reaction (PCR). If droplets would break during the initial stages of amplification, all of the information from different droplets would get mixed in the tube and the knowledge about which activity belongs to which sequence would be lost, as it was not yet recorded by the means of amplification (before the amplification, the activity measurement information is in form of modified substrate nucleotides).
That is why CAT-Seq uses a multiple displacement amplification (MDA), which is a non-thermocycling (isothermal) based DNA amplification technique. MDA was chosen because of its ability to rapidly amplify single templates of DNA into long double-stranded molecules which contain multiple repeats of the starting template. That said, one of the core requirements of MDA reaction is that starting DNA template must be circular.
2. Secondly, as seen in the later steps of CAT-Seq, in order to efficiently express a catalytic biomolecule in droplets, Rolling Cycle Transcription (described in catalytic biomolecule production section) is used, which immensely increases mRNA synthesis yield from a single DNA template. Such technique also requires the DNA to be circular, as an RNA polymerase travels around it in circles producing mRNA.
Proof of concept
Choosing the first catalytic biomolecule for creating and optimizing CAT-Seq system was a classical “chicken or the egg” paradox. At the very beginning, when system design was purely theoretical and we have been preparing to build it, the main question we had was - what is the combination of substrate nucleotide and catalytic biomolecules we should use, in order to confidently know if our system or its parts are working as intended?
For example, if we would have tried to build CAT-Seq using a random library of different catalytic biomolecules and at the same time tested the system performance, we would have no idea whether if it’s the catalytic biomolecule and substrate nucleotide combination that is influencing our positive or negative results, or is it the CAT-Seq method itself. In other words, we had two groups of variables. For that reason, we wanted to reduce the variables to one group - system performance variables.
In order to achieve that, we have decided to use standard, already well established low-throughput methods to find a particular catalytic biomolecule and a substrate nucleotide pair. After that, we can then use that well-characterized catalytic biomolecule and substrate pair to build and optimize CAT-Seq.
Obtaining the first catalytic biomolecule
In order to find a correct combination of Substrate Nucleotide and the Catalytic Biomolecule that can catalyze the removal of the substrate, we have decided to look for a hydrolase. The is because a direct removal of the substrate from nucleotide seemed like the most timewise efficient choice.
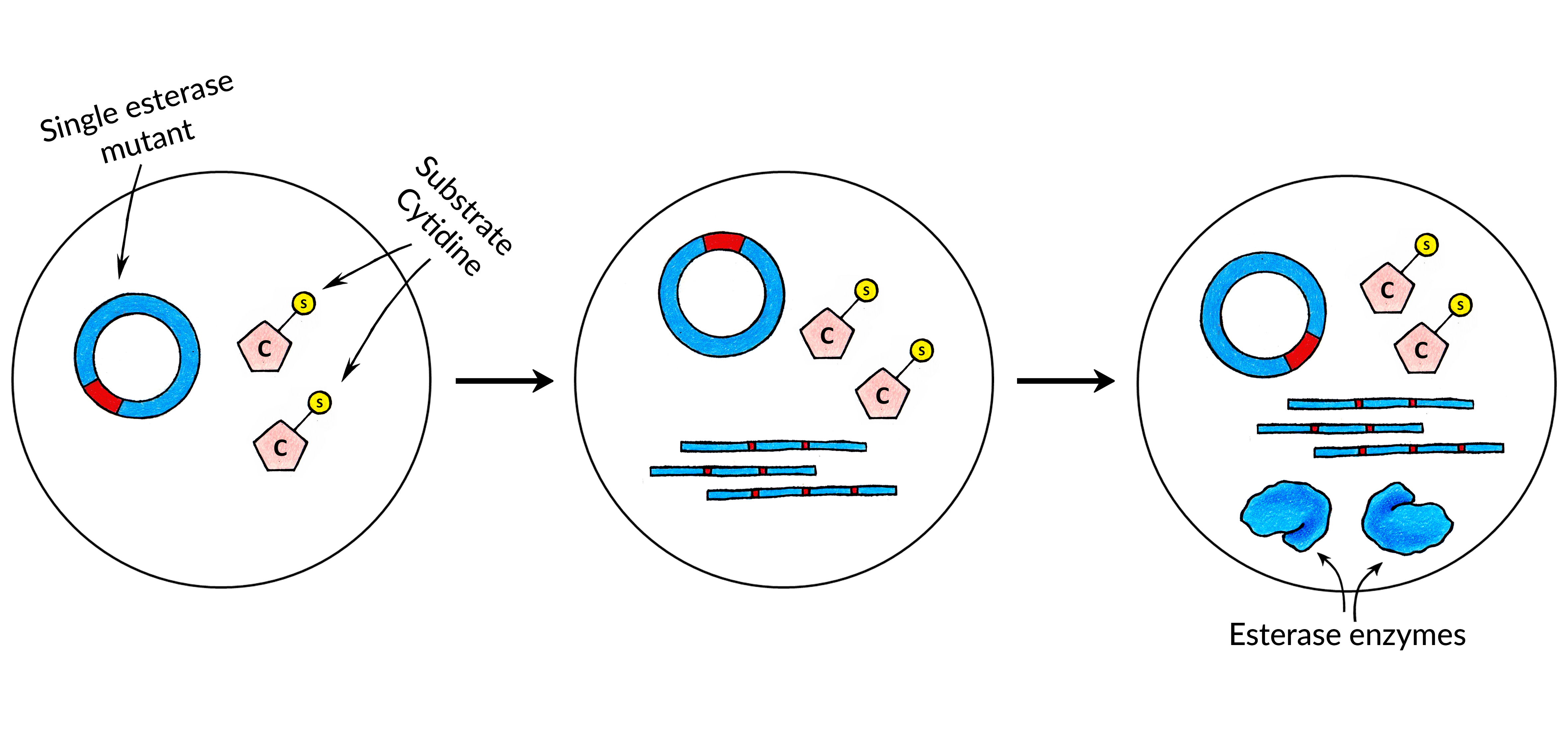
First, we synthesized a cytidine which had a benzoyl substrate attached to it: N4-benzoyl-2'-deoxycytidine triphosphate. Instructions on how such substrate nucleotide can be synthesized can be found here.
Then, an esterase library was screened manually using microwell plates in order to find the hydrolase enzyme which can catalyse the removal of the substrate. Once such enzyme was found and its sequence was determined. We have then used this pair of esterase enzyme and substrate cytidine to build the first version of CAT-Seq.

Next, we have performed an in-silico modelling of our Esterase enzyme. The goal of the in-silico analysis was to create the Esterase mutants which would have different catalytic activities. Once such mutants were constructed, their relative catalytic activities were measured again using the same standard methods we have used to find the initial esterase enzyme. This was done in order to construct a small Esterase mutant library which would have precisely-defined catalytic activities by already established low-throughput measuring methods. Then, with CAT-Seq, we can also measure the activities of those mutants in high-throughput, which can then be compared to our previous measurements to confirm that CAT-Seq system is working as intended and can precisely discriminate different mutant activities.
After acquiring the esterase enzyme and its mutants, regulatory sequences - RNA polymerase promoter and ribosome binding site - were added to each of the library members. Then, the fragments were circularized for the MDA and RCT reactions.
After acquiring the initial esterase for building CAT-Seq, why were the mutations added manually and not randomly?
The goal of the in-silico modelling of the esterase was to determine mutants that would have different catalytic activities. If we had a randomized library of esterase mutants, it would have been difficult to precisely tune CAT-Seq parts as we would not be sure what output of the system we should expect. In contrast, having mutants with precisely measured catalytic activities beforehand using well-established and precise low-throughput methods enables us to recognise how well our system is performing.
For example, if mutant A was determined to be a little bit more active then mutant B, CAT-Seq would have to be sensitive enough to discriminate the difference and also precise enough to determine that mutant A is indeed more active then mutant B.
General description
For the precise measurement of multiple biomolecule’s catalytic activities they need to be physically separated. For example, if we would want to measure the activities of two mutants, we probably would not mix them together - we would measure them in separate tubes. The same logic applies with bigger libraries. Droplet microfluidics offers a way to quickly parallelize billions of reactions by physically separating reactants in pico- to nano-liter water droplets.
Using a microfluidic device chip whole DNA library can be encapsulated into the droplets, together with specific reaction reagents. Water phase flows through the microfluidic device channels with the help of pressure created by special pumps.

As water passes through oil flow, it breaks into defined size droplets. Their size depends on dimensions of the device, water and oil flow rates. On average, 300 000 of droplets can be generated in under 10 minutes. Generated droplets are collected into a simple 1.5mL tube and can be incubated at a required temperature or stored in a fridge.
In CAT-Seq, multiple of things must be encapsulated into the droplets:
1. Catalytic Biomolecule Library - in the form of nucleic acids or cells that encode a particular catalytic biomolecule library.
2. Reagents for biomolecule production - described with more details in later sections.
3. Substrate Nucleotides - the target for catalytic biomolecule. It can be attached to any of the four dNTPs. All four different nucleotides can be used in order to record the activity information using 4 different substrates.
The goal of the catalytic biomolecule is to recognise the substrate and catalyze a particular chemical conversion which depends on the substrate and biomolecules type. In many cases such conversion helps the substrate to detach from the nucleotide. Such detachment can be achieved by the first catalyzed reaction or subsequent spontaneous reactions that follow the initial one.

Please see the Methods and Protocols section for a more detailed description of microfluidics techniques.
Proof of concept
As we have already chosen a combination of esterase enzyme and a substrate nucleotides, our initial encapsulation consisted of following:
1. Esterase mutant library created with the help of in-silico modelling.
2. In-vitro transcription and translation (IVTT) mix for catalytic biomolecule production.
3. Substrate Nucleotides (N4-benzoyl-2'-deoxycytidine triphosphates) as the targets for the esterase enzyme.
How such encapsulation looks can be seen in the video below:

After the encapsulation each droplet on average contains single copy of a mutant DNA sequence from the Esterase library. Also every droplet contains the same amount of IVTT reagents and Substrate Nucleotides. We call these droplets the Substrate Droplets.
In order to ensure the fidelity of the data collected using CAT-Seq only every 10th droplet houses a DNA template after droplet generation. If the concentration of DNA molecules in the starting encapsulation mix is too high, the likelihood of encapsulating multiple mutant templates per droplet increases drastically. Such events disrupt the data acquired by CAT-Seq or any droplet microfluidics technique. Encapsulation events can be precisely described by Poisson distribution:

P(X = k) is the probability for the single droplet to house k DNA molecules. λ shows the average number of DNA molecules per droplet. For example, if you want to have a single template per droplets, you might choose λ to be 1. The Poisson distribution predicts, that 36.7% of droplets will have one molecule. However, it also predicts that 18.4% of droplets will house 2 molecules and 6.1% - 3 molecules. Following this notation, In order to avoid artificial data, caused by multiple DNA templates in one droplet, the concentration of the DNA template was kept at 1 per 10 droplets (λ = 0.1). As seen from the graph, 90.4% of droplets will be empty and 9% will have 1 template. On the other hand, 0.4%. of droplets will house 2 DNA molecules, meaning that droplets with 2 DNA templates are generated rarely

General description
Once the encapsulation is finished, biomolecules are then produced in the droplets. In principle, there are two major approaches of producing catalytic biomolecule in the CAT-Seq system:
1. Nucleic Acids: encapsulating DNA or RNA molecules encoding the catalytic biomolecule. After the encapsulation the droplets can be incubated in order to produce the biomolecule. If the catalytic biomolecule is an enzyme, in-vitro protein synthesis (A) kit can be used in order to produce it. Otherwise, if it is a Ribozyme (B), it can be produced using in-vitro transcription reagents. Also, there are cases where the catalytic biomolecule is a Deoxyribozyme (C). Then, all that is required is to encapsulate the DNA library!

During one of the collaborative meetings with experts from microfluidic technology field in Life Sciences Center located in Vilnius, we have received information that synthesizing biomolecules from a single DNA template is an extremely inefficient process. That is because when there is only a single template of DNA, the mRNA synthesis yield is extremely low and there is not enough mRNA to make an enzyme.

After doing in-depth literature research to try to solve this problem, we have found out that around 1990s people immensely increased short microRNA synthesis yields by circularizing DNA templates. As RNA polymerase goes around the DNA in circles it produces long strands of RNA molecules. Within those long molecules were the repeating small units of microRNA. They coined this method Rolling Circle Transcription (RCT).

Following this discovery, we have figured out we can apply RCT in order to fix the current fundamental issues with biomolecule expression from single DNA templates in the field of droplet microtechnologies. As we are already circularizing DNA molecules in order to perform the MDA reaction in later steps, all that is left to do is to remove the transcription terminator from the catalytic biomolecule library members. Such removal of the terminator highly increases the mRNA concentration from a single template. Therefore, enzymes can then be efficiently synthesized using a single template of DNA.

2. Cells: catalytic biomolecules can also be provided into droplets in the form of cells, which have the DNA library transformed into them (one library variant per cell on average). In turn, the cells may produce the protein of interest. After cells are encapsulated into droplets, cell-specific reagents can lyse the cells. After the cell lysis, an enzyme of interest is released into the droplet together with DNA molecules that encoded it.

Proof of concept
After the esterase mutant DNA library and Substrate Nucleotides are encapsulated together with protein expression reagents the droplets are incubated in order for protein expression to occur.
General description
At this stage, each droplet contains produced catalytic biomolecules. These catalytic biomolecules can now act on Substrate Nucleotides. After the chain of catalyzed chemical reactions is over, some of the nucleotides have their substrates removed - they are now Product Nucleotides. Depending on the catalytic biomolecule activity in each droplet, there can be a different amount of product nucleotides depending on the activity of the biomolecule variant.

Proof of concept
In each droplet esterase mutants are synthesized. Depending on their activities, they will remove different amount of substrates from the Substrate Cytidines in different droplets.

Not at all! CAT-Seq allows to screen biomolecules catalyzing numerous of distinct reactions. Please head to the Substrate Nucleotide design page for more information and examples!
General description
At this point, each droplet contains a defined amount of nucleotides with their substrate removed, which is proportional to how strong the catalytic activity was in the particular droplet, of that particular biomolecule.
This information must then be stored into the biomolecule coding DNA sequence in the process of DNA amplification.
There are two main things that need to be considered in order to precisely record the activity information: effective DNA amplification and the addition of reference information which would serve as an activity baseline or a point of reference.
First of all, the efficiency of amplification reaction. After an in-depth discussion with microfluidics expert Karolis Leonavičius we have decided that DNA amplification reagents must be added after the initial droplet generation and protein production. That is because protein synthesis reagents usually do not work well with various amplification mixes.
Droplet merging can solve this problem. Main principle of droplet merging techniques, is that by using a specially designed microfluidics device, droplets can be merged with the help of electrical field. In CAT-Seq, the initial population of substrate droplets must be merged with freshly generated amplification droplets. All the the amplification droplets contain the same amount of reagents that are required to amplify DNA.

Another important thing to consider is creating a reference point which would help to precisely determine the activities of different catalytic biomolecules. For CAT-Seq, such reference point is nucleotides with reference modification. This modification can be any small modification which still allows a DNA polymerase to incorporate it during the amplification. We call them the Reference Nucleotides.
For example, If we would try to amplify DNA template in each droplet that contains different amounts of nucleotides that can be incorporated, we would get a sequencing bias that would be more favourable for biomolecules that are highly active.

That is because biomolecules with higher activity would produce more nucleotides for polymerase and the amplified DNA amount would be much bigger than compared to lower activity mutants which would produce less. Reference nucleotides can easily remove this bias - after merging the Substrate Droplet with Amplification droplets that contain Reference Nucleotides, they allow the synthesis of a similar amount of amplified DNA in each droplet.

Thus, two important parts of CAT-Seq has now been established - droplet merging and Reference Nucleotides.
Going back, we now have a population of substrate droplets that have a defined amount Product Nucleotides (the chemically converted substrate nucleotides). Those must then be merged with Amplification Droplets, wherein every droplet contains the same amount of amplification reagents and Reference Nucleotides. After the droplet merging, each droplet now contains a ratio of Product nucleotides to Reference Nucleotides. If the catalytic biomolecule was highly active, the ratio of Product Nucleotides to Reference Nucleotides will be high. In contrast, if the biomolecule activity was low, the ratio will also be low.

These specific nucleotide ratios in droplets can then be recorded into DNA, by the means of DNA amplification. As DNA is amplified in each droplet, specific ratio of nucleotides is incorporated into the copy of initial template. Such amplification results in molecules that both encode the sequence of a specific biomolecule and information about that particular biomolecules’ catalytic activity.

Proof of concept
We now have a population of droplets, wherein each droplet contains a specific amount of Product Nucleotides or 2'-deoxycytidine triphosphates.
As already mentioned earlier, we have chosen to use MDA reaction in order to amplify the DNA isothermally. Isothermal amplification allows us to amplify the DNA without disrupting the stability of the droplets. Also, for the Reference Nucleotides, we have decided to use Methylated Cytidines (2'-deoxy-5-methylcytidine 5'-triphosphates). These Reference Nucleotides can be readily incorporated by multiple polymerases, including Phi29 which we use for our MDA reaction.
Next, we need to merge our Substrate Droplets with the Amplification Droplets containing the MDA reaction mix. Droplet merging is not an easy task to achieve, as efficient merging requires precise tuning of multiple parameters, such as 4 different droplet and oil flow rates and the strength of the electrical field that helps the droplets to merge. Searching for these parameters experimentally can often be like searching for a needle in a haystack. For this reason, before starting to do droplet merging experiments in the laboratory, we have written a thorough mathematical model which describes the droplet merging in detail and has the ability to predict the correct experimental parameters. We have successfully determined those parameters and showed experimentally, that they were indeed well-performing conditions for the droplet merging.
Substrate Droplets could then be merged with Amplification Droplets containing MDA mix and Reference Nucleotides.
Each merged droplet now contains a specific ratio of Product Cytidines to Methylated Cytidines. Such information can then be recorded by initiating MDA reaction. After the reaction, the amplified DNA molecules now have the specific ratio of nucleotides, wherein the ratio of those nucleotides depend on the specific esterase mutant activity.

General description
The last step of the CAT-Seq is the retrieval of recorded activity information from the amplified DNA. In theory, this may be achieved by any sequencing method that can incorporate a DNA modification recognition step. Yet, CAT-Seq uses Nanopore Sequencing for several reasons:
1. Nanopore sequencing allows to sequence long molecules, which eliminates the need of biomolecule fragmentation. This is an extremely important characteristic to us because when working with large libraries of mutants in single droplets, fragmenting amplified DNA in those droplets means that all of those fragments in droplets would need to be barcoded. While in theory, this is a possible thing to do, it would require an extra merging and amplification step which would immensely decrease the accuracy of the activity determination. That is because in general, every step of the biotechnological method never is one hundred percent efficient. In turn, the lower amount of steps your system needs to take in order to produce results - the more accurate it will be. That is why reducing the number of steps in CAT-Seq by omitting fragmentation and barcoding was extremely important for us.
2. Secondly, nanopore sequencing can detect and discriminate different modified nucleotides with ease, because nanopore can detect slight changes in nucleotide structure and assign a different value to that signal.
Going back, the droplets containing the amplified DNA molecules can then be broken and the amplified DNA is purified. The purified DNA from water phase can be directly sequenced using a nanopore sequencer. As the library passes through the nanopore, it retrieves the biomolecule’s sequence and the information about its activity that is encoded in the form of Product to Reference Nucleotide ratio.

Using the same principle, billions of different catalytic biomolecule sequences and their corresponding activities can be recorded.

Proof of concept
The last step of the proof of concept story is the sequencing of amplified DNA using the nanopore. This is an important step, because it can provide the information about the CAT-Seq system precision. In this case, nanopore must accurately distinguish mutant sequences that contain different point mutations and accurately detect Product and Reference Cytidines.

After the sequencing we have successfully retrieved information about both the different mutant sequences and also their activities. After that, it was extremely important to compare the sequences and activities retrieved by CAT-Seq and the precise, low-throughput esterase mutant measurements we have performed earlier using standard methods. The proof of concept was a huge success, as activities determined by CAT-Seq closely followed the beforehand low-throughput measurements by standard methods.

To read about more about proof of concept results, please click here.