Difference between revisions of "Team:Tongji-Software/Model"
| Line 272: | Line 272: | ||
<span class="detail">We define the normalized Boltzmann factor for r as f(r) :</span></br> | <span class="detail">We define the normalized Boltzmann factor for r as f(r) :</span></br> | ||
| − | < | + | <b>∆_r G^('°): the standard reaction Gibbs energy</br> |
| − | < | + | <b>RN: a set of native reactions that can transform C in a given host organism</br> |
| − | < | + | <b>R : gas constant </br> |
| − | < | + | <b>T : absolute temperature</br> |
<img src="https://static.igem.org/mediawiki/2018/8/8b/T--Tongji-Software--model4.png" width ="80%"></br> | <img src="https://static.igem.org/mediawiki/2018/8/8b/T--Tongji-Software--model4.png" width ="80%"></br> | ||
<span class="top">Fig.4. If r∈R_N , then f(r) is simply based on the Boltzmann distribution of the native reaction system transforming compound C. If r∉R_N, then f(r) is based on the Boltzmann distribution of the reaction system that contains all native reactions transforming C and foreign reaction r.</span></br> | <span class="top">Fig.4. If r∈R_N , then f(r) is simply based on the Boltzmann distribution of the native reaction system transforming compound C. If r∉R_N, then f(r) is based on the Boltzmann distribution of the reaction system that contains all native reactions transforming C and foreign reaction r.</span></br> | ||
| + | <img src ="https://static.igem.org/mediawiki/2018/7/77/T--Tongji-Software--model7.gif" width="80"></br> | ||
<span class="detail">For each pathway, every reaction r in the pathway has the score log f(r)</span></br> | <span class="detail">For each pathway, every reaction r in the pathway has the score log f(r)</span></br> | ||
Revision as of 12:38, 5 October 2018









Model
Overview
We will introduce how we use knowledge of mathematics and algorithms to implement function of Alpha Ant in details in this section. It consists of three parts, Pathway Search Algorithm, Pathway Ranking Methods and Additional functions.
Pathway Search Algorithm: Depth-first search
Seeking for biosynthesis pathways from the starting material to the product is a typical search problem. We abstracted the original biosynthesis pathway search problem and turned it into a directed graph search problem.
First we built a directed graph that models the transformation of metabolites where its vertices represent metabolites and its edges represent chemical transformations via reactions.
 Fig.1. Search algorithm:DFS(Depth-first Search)
Then we used the Depth-first search algorithm to traverse and search this graph data structures. Not only do we need to get all of the solutions that satisfy the constraints, but also need to record the search path. The DFS algorithm starts at the root node and explores as far as possible along each branch before backtracking. The search remembers previously visited nodes and will not repeat them therefore avoiding infinite loop. As a result, all solutions that satisfy the constraints will be returned.
The procedure of DFS is described as follows:
The reason we choose this algorithm is that it can solve the pathway search problem efficiently. Based on adjacency matrix, DFS algorithm can solve the problem within the time complexity of O (E + V).[1] ‘E’ means the number of edges and ‘V’ means the number of vertex, and we are able to solve the problem by traversing all the edges and vertex just only once. Moreover, the core algorithm of DFS is flexible, so that we can combine it with other evaluation algorithms to solve more complex problems.
Pathway Ranking Criteria
We adopt three criteria to evaluate the efficacy of the pathways which are thermodynamic feasibility& precursor competition, toxicity of metabolites and atom conservation. After grading pathway using different criteria, we normalize the scores and give users the right to define different weights of different ranking criteria.
The criterion of thermodynamic feasibility& precursor competition:
We use a statistical mechanical model to present the competition for a metabolic precursor with endogenous reactions. We compute the probability of each reaction with ∆_r G^('°) ( the standard reaction Gibbs free energy) through the Boltzmann distribution according to study of Hiroyuki Kuwahara et.al[5]. Here is the mathematical description.
Fig.1. Search algorithm:DFS(Depth-first Search)
Then we used the Depth-first search algorithm to traverse and search this graph data structures. Not only do we need to get all of the solutions that satisfy the constraints, but also need to record the search path. The DFS algorithm starts at the root node and explores as far as possible along each branch before backtracking. The search remembers previously visited nodes and will not repeat them therefore avoiding infinite loop. As a result, all solutions that satisfy the constraints will be returned.
The procedure of DFS is described as follows:
The reason we choose this algorithm is that it can solve the pathway search problem efficiently. Based on adjacency matrix, DFS algorithm can solve the problem within the time complexity of O (E + V).[1] ‘E’ means the number of edges and ‘V’ means the number of vertex, and we are able to solve the problem by traversing all the edges and vertex just only once. Moreover, the core algorithm of DFS is flexible, so that we can combine it with other evaluation algorithms to solve more complex problems.
Pathway Ranking Criteria
We adopt three criteria to evaluate the efficacy of the pathways which are thermodynamic feasibility& precursor competition, toxicity of metabolites and atom conservation. After grading pathway using different criteria, we normalize the scores and give users the right to define different weights of different ranking criteria.
The criterion of thermodynamic feasibility& precursor competition:
We use a statistical mechanical model to present the competition for a metabolic precursor with endogenous reactions. We compute the probability of each reaction with ∆_r G^('°) ( the standard reaction Gibbs free energy) through the Boltzmann distribution according to study of Hiroyuki Kuwahara et.al[5]. Here is the mathematical description.
 Fig.3. We consider C as the metabolic precursor. Let RN be a set of native reactions that can transform C in a given host organism and Rr is the reaction in the pathway to be evaluated.
The Boltzmann factor of reaction r that can transform C :
Fig.3. We consider C as the metabolic precursor. Let RN be a set of native reactions that can transform C in a given host organism and Rr is the reaction in the pathway to be evaluated.
The Boltzmann factor of reaction r that can transform C :
 We define the normalized Boltzmann factor for r as f(r) :
∆_r G^('°): the standard reaction Gibbs energy
RN: a set of native reactions that can transform C in a given host organism
R : gas constant
T : absolute temperature
We define the normalized Boltzmann factor for r as f(r) :
∆_r G^('°): the standard reaction Gibbs energy
RN: a set of native reactions that can transform C in a given host organism
R : gas constant
T : absolute temperature
 Fig.4. If r∈R_N , then f(r) is simply based on the Boltzmann distribution of the native reaction system transforming compound C. If r∉R_N, then f(r) is based on the Boltzmann distribution of the reaction system that contains all native reactions transforming C and foreign reaction r.
Fig.4. If r∈R_N , then f(r) is simply based on the Boltzmann distribution of the native reaction system transforming compound C. If r∉R_N, then f(r) is based on the Boltzmann distribution of the reaction system that contains all native reactions transforming C and foreign reaction r.
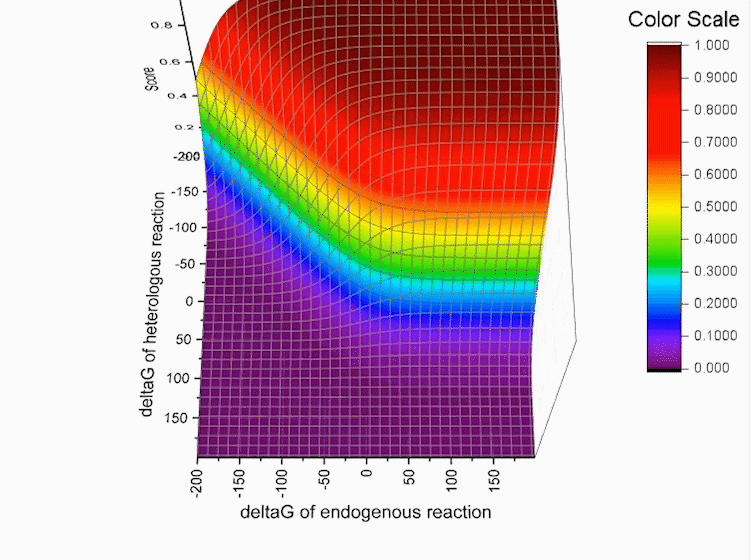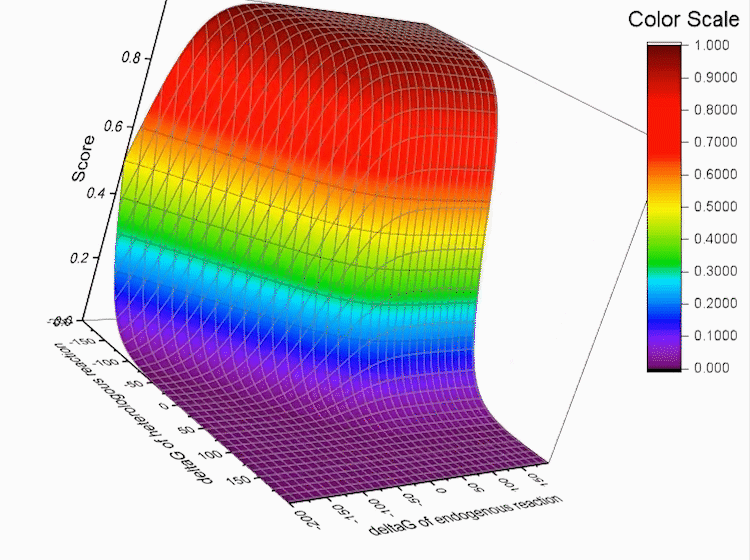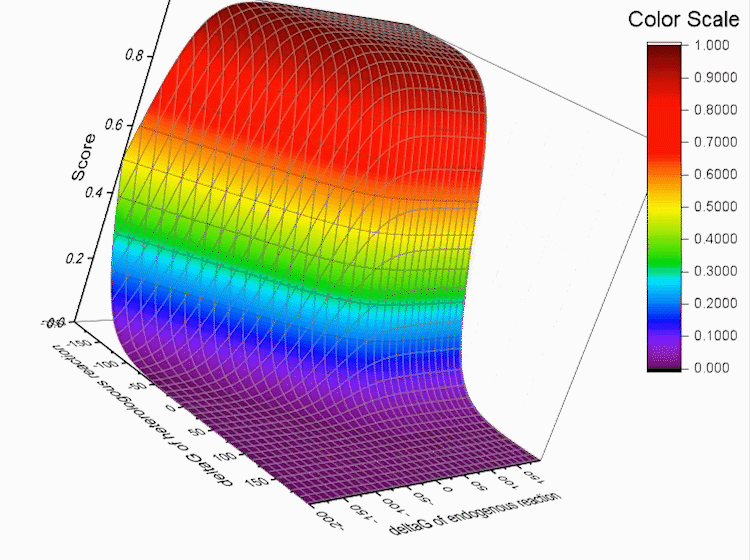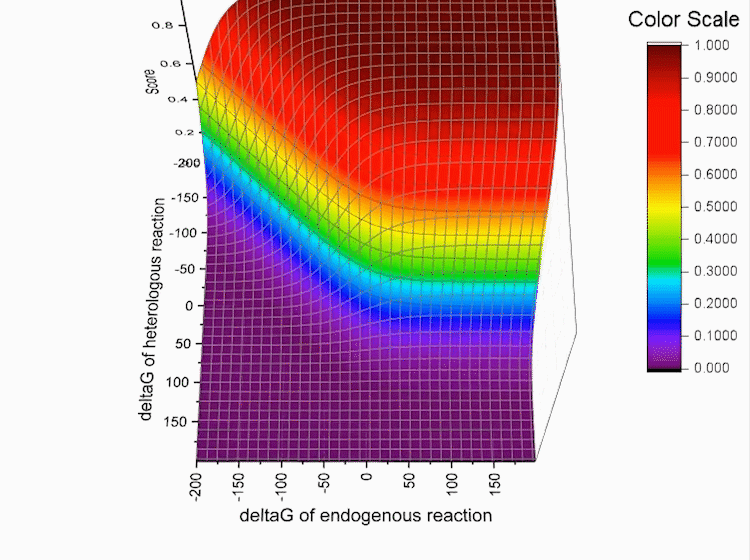 For each pathway, every reaction r in the pathway has the score log f(r)
The score of the pathway is as follows:
For each pathway, every reaction r in the pathway has the score log f(r)
The score of the pathway is as follows:
 Fig.5. Every reaction r in the pathway has the score log f(r),S refers to total score.
S is used to evaluate the pathway. The higher the score is, the better the pathway is.
Atom conservation
There is a one-to-one correspondence between atom index from reactant and atom index from product in MetaCyc. We integrated the data form into the main pairs in KEGG. We cleaned and removed the redundant data. In one pathway, each step of the reaction is recursive, leaving only the atomic number derived from the source compound, and the rest of the positions are -1. Finally, you can calculate how many atoms in the target are from the source compound.
Additional function algorithm
Microorganism recommendation
After searching the pathways, we first select some pathways and then use previous scoring method to calculate each route’s score of certain organism. Next we rank the average score of all species and the highest is the best. The number of the selected pathways n can be defined by users. The default value is 50.
Fig.5. Every reaction r in the pathway has the score log f(r),S refers to total score.
S is used to evaluate the pathway. The higher the score is, the better the pathway is.
Atom conservation
There is a one-to-one correspondence between atom index from reactant and atom index from product in MetaCyc. We integrated the data form into the main pairs in KEGG. We cleaned and removed the redundant data. In one pathway, each step of the reaction is recursive, leaving only the atomic number derived from the source compound, and the rest of the positions are -1. Finally, you can calculate how many atoms in the target are from the source compound.
Additional function algorithm
Microorganism recommendation
After searching the pathways, we first select some pathways and then use previous scoring method to calculate each route’s score of certain organism. Next we rank the average score of all species and the highest is the best. The number of the selected pathways n can be defined by users. The default value is 50.

Fig.1. Search algorithm:DFS(Depth-first Search)
Then we used the Depth-first search algorithm to traverse and search this graph data structures. Not only do we need to get all of the solutions that satisfy the constraints, but also need to record the search path. The DFS algorithm starts at the root node and explores as far as possible along each branch before backtracking. The search remembers previously visited nodes and will not repeat them therefore avoiding infinite loop. As a result, all solutions that satisfy the constraints will be returned.
The procedure of DFS is described as follows:
The reason we choose this algorithm is that it can solve the pathway search problem efficiently. Based on adjacency matrix, DFS algorithm can solve the problem within the time complexity of O (E + V).[1] ‘E’ means the number of edges and ‘V’ means the number of vertex, and we are able to solve the problem by traversing all the edges and vertex just only once. Moreover, the core algorithm of DFS is flexible, so that we can combine it with other evaluation algorithms to solve more complex problems.
Pathway Ranking Criteria
We adopt three criteria to evaluate the efficacy of the pathways which are thermodynamic feasibility& precursor competition, toxicity of metabolites and atom conservation. After grading pathway using different criteria, we normalize the scores and give users the right to define different weights of different ranking criteria.
The criterion of thermodynamic feasibility& precursor competition:
We use a statistical mechanical model to present the competition for a metabolic precursor with endogenous reactions. We compute the probability of each reaction with ∆_r G^('°) ( the standard reaction Gibbs free energy) through the Boltzmann distribution according to study of Hiroyuki Kuwahara et.al[5]. Here is the mathematical description.
Fig.3. We consider C as the metabolic precursor. Let RN be a set of native reactions that can transform C in a given host organism and Rr is the reaction in the pathway to be evaluated.
The Boltzmann factor of reaction r that can transform C :
We define the normalized Boltzmann factor for r as f(r) :
∆_r G^('°): the standard reaction Gibbs energy
RN: a set of native reactions that can transform C in a given host organism
R : gas constant
T : absolute temperature
Fig.4. If r∈R_N , then f(r) is simply based on the Boltzmann distribution of the native reaction system transforming compound C. If r∉R_N, then f(r) is based on the Boltzmann distribution of the reaction system that contains all native reactions transforming C and foreign reaction r.
For each pathway, every reaction r in the pathway has the score log f(r)
The score of the pathway is as follows:
Fig.5. Every reaction r in the pathway has the score log f(r),S refers to total score.
S is used to evaluate the pathway. The higher the score is, the better the pathway is.
Atom conservation
There is a one-to-one correspondence between atom index from reactant and atom index from product in MetaCyc. We integrated the data form into the main pairs in KEGG. We cleaned and removed the redundant data. In one pathway, each step of the reaction is recursive, leaving only the atomic number derived from the source compound, and the rest of the positions are -1. Finally, you can calculate how many atoms in the target are from the source compound.
Additional function algorithm
Microorganism recommendation
After searching the pathways, we first select some pathways and then use previous scoring method to calculate each route’s score of certain organism. Next we rank the average score of all species and the highest is the best. The number of the selected pathways n can be defined by users. The default value is 50.