It is also a good rule not to put too much confidence in
experimental results until they have been confirmed by
Theory.
-- Sir Arthur Eddington
 This wordplay by Sir Arthur Eddington highlights the importance of math-based models in every discipline of science. In Physics, the incredible potential of math has long been known and utilized. Chemistry was lacking behind a bit, but there is an incredible theoretical branch of chemistry that took a lot out of methods rooted in physics. Biology is, sadly, lacking behind its sister sciences.
Every theory and every model only realizes its full potential with experimental confirmation while experimental results can be achieved without any model. But in conjunction with each other, the boundaries of science can be heightened dramatically.
This wordplay by Sir Arthur Eddington highlights the importance of math-based models in every discipline of science. In Physics, the incredible potential of math has long been known and utilized. Chemistry was lacking behind a bit, but there is an incredible theoretical branch of chemistry that took a lot out of methods rooted in physics. Biology is, sadly, lacking behind its sister sciences.
Every theory and every model only realizes its full potential with experimental confirmation while experimental results can be achieved without any model. But in conjunction with each other, the boundaries of science can be heightened dramatically.
Our Project is centered around saving time, streamlining processes and offering these advantages to the community. We improved processes to run faster, but another way that should be implemented in parallel is predicting what to test in the lab and therefore eliminating unnecessary experiments. The most powerful process that allows for improved prediction power or is the reason that prediction is even possible is modeling. We harvested this prediction power with two independent modeling approaches, one predicting the metabolism of Vibrio Natriegens and the other designing an enzyme capable of a novel reaction, decarboxylating malate to 3-hydroxypropionic acid ( 3HPA).
Metabolic Model
In order to be able to fine-tune synthetic pathways and utilize the well-characterized parts of our cloning toolbox to its fullest potential, we need a model which gives useful predictions of metabolic fluxes. There exists a multitude of approaches to model fluxes – some are on the genomic scale some occupied only with the mechanism of a single enzyme. We have chosen to utilize two different approaches – on one scale we use reaction kinetics to analyze the behavior/kinetics of our inserted enzymes within the metabolism – on the other we use a novel approach called 2S-MFA [Reference] to get a genome-scale perspective on the metabolic fluxes. Using the thereby consolidated theoretical knowledge we can complete the Design-Build-Test-Learn cycle for our metabolic engineering project and use it to iteratively improve our project. With the prediction power of this models, we not only save a lot of time in the lab but we manage to improve the efficiency and productivity, the skill ceiling of our pathway.
Structural Model
The pathway we used for production of 3HPA (LINK ZU Metabolic) has been explored previously and is based on a combination of known reactions and known enzymes. Combination of different enzymes to make a synthetic pathway is a well-established method in the field of metabolic engineering, but limited to existing reactions and known enzymes. With our structural model, we tried to build a new energetically more favorable pathway which was previously impossible. To accomplish that, we needed to implement a reaction with no known enzyme to catalyze it, the decarboxylation reaction of malate to ( 3HPA). To build this pathway we decided to engineer an enzyme capable of catalyzing this reaction. We performed a literature research and developed an idea on how to build a binding pocket catalyzing this reaction. To evaluate if our binding pocket works, we performed electronic structure calculations. With that, we were able to calculate the activation barrier of the reaction and therefore evaluate if it is possible for the reaction to take place. To advance from a binding pocket to a full enzyme we evaluated in silico mutated versions of acetolactate decarboxylase (ALD). For evaluating which mutants perform best we used MD simulations and checked how well the binding pocket assumed in the electronic structure calculations is represented in the simulations. With the help of these in silico approaches we chose a mutant and tested it in the wetlab.
Teach the rabbit to quack
Expanding the scope of Metabolic Engineering through novel enzyme engineering
Infrastructure
We want to thank Prof. Klebe and Prof. Kolb for kindly providing us with the necessary infrastructure and software access to perform our calculations. For our QM calculations, we used the program GAUSSIAN09 and Chemcraft to set up our systems. For a foray to how these kinds of calculations work, please click here.
Foray to QM Calculations []
QM Calculations are the pinnacle of precision compared to all other methods used for calculating molecular systems, but this precision comes with very high computational costs. What the computer actually does when doing this type of calculations is calculating the Hamiltonian of the system and solving the Schroedinger Equation that way. With the help of this, we can describe the system. QM Calculations are characterized by two important things, the functional and the basis set used. The functional is characterized by the way the Hamiltonian is calculated. For all calculations that we do, we also need a starting point to describe orbitals or the density function (We will go into more detail to this later) and the basis set describes the number and type of the orbital functions that we use to calculate the system.
Born Oppenheimer Approximation
A necessary assumption to use QM as well as MM methods is the Born Oppenheimer Approximation. This is the approximation that due to the vast difference in speed between the electrons and the nucleus of the atoms the movement of both can be investigated apart from each other. For QM Methods this means that we only look at the movement of electrons and neglect the very slow movements of the nuclei when solving the Schroedinger Equation.
Functionals and Basis sets
Functionals
There are two fundamentally different type of functionals, wave function based and density function based methods.
We only used density function based methods, to be precise B3Lyp.
Density Function Theory (DFT) is centered not on the Wavefunction but on the square of the wave function, the electron density.
It is based on the theorem of Hohenberg and Kohn and modern DFT is also based on the Kohn Sham approach.
The electron density is a measurable quantity that is dependent on the three vectors of spaces.
In the first days of DFT (when invented by physicists) mostly the Linear Density Approach (LDA) was used and this approach works fine for metals, in which the electrons are evenly distributed inside the metal.
However, this is a poor approximation once we want to model molecular systems.
As a further Development of this approximation, Gradient corrected methods (GGA) have been invented.
These methods consider the electron density not to be uniform.
There are multiple terms in the Hamiltonian that have to be calculated.
The most troublesome one is the so-called "Exchange-Correlation" term.
There is a class of DFT functionals, the so-called Hybrid Functionals, that use a combination of exchange-correlation terms of different methods.
The method we used, B3LYP, uses a combination of LDA, GGA and Hartree Fock (A wavefunction based method) exchange-correlation.
Basis Sets
Now that we know which method we use we can take a look at the second important characteristic of our QM calculations, the basis set. All methods described previously, even if based on DFT, use Orbitals in their calculations. By combining a certain number of Orbitals the orbitals of the system have to be expressed. This starting number of orbitals is called the basis set. Obviously, the more orbitals we have the more accurate the calculations become, but they also get more demanding. As a small basis set we used the 6-31g variant and as a bigger basis set, we used cc-pVDZ.
Summary
- Based on Quantum Mechanics
- All electrons investigated
- Bond cleavage and formation can be calculated
- Slow Calculations and limited to small Systems
Foray to Molecular Mechanics
Molecular Mechanics (MM ) uses the laws of classical mechanics to model molecular systems. It can be used to calculate anything ranging between small molecules to big proteins. Each atom is simulated as one single particle, with a radius and charge. Bonded interactions are treated by the famous Hookes law (i.e. they are springs). This approximation allows us to simulate very big systems, but it is very important to asses which properties we can simulate correctly and therefore investigate. Because classical Molecular Dynamics (MD) Simulations are based on MM , we cannot simulate bond breaking or bond formation which also means that protonation states cannot change during simulation.
Force Fields
To calculate inter- and intramolecular interactions, so-called force fields are used.
With these FF all of these interactions are reduced to single additive terms.
It consists of terms for bond stretching, angle bending, torsions, Lennard-Jones potential (for Van-der-Waals interactions) and electrostatic potential.
It is necessary to parametrize these terms very carefully and this is done by using experimental data or QM calculations.
There are many FF available and we used a force field from the AMBER family called ff14SB (Maier et al.2015).
The complete potential function is given in the following equation:

Kinetic Energy and Time Evolution of a molecular system
If we would just apply all of the physical principles and assumptions mentioned previously, we would minimize the system to the closest potential energy minimum.
For the system to overcome potential energy barriers given by the FF, we have to introduce kinetic energy.
The kinetic energy of all particles in the system is dependent on their temperature and given by a Maxwell-Boltzmann velocity distribution function.

This distribution function contains the kinetic energy of a particle, which is expressed as its momentum.

The total energy of the system is given as the sum of the potential energy (given by the force field) and the kinetic energy.
Each particle in every MD time that we investigate has, therefore, three positional coordinates, three momentum coordinates, and a corresponding total energy.

To now introduce time evolution in the system we use classical mechanics and newtons laws of motion in combination with the kinetic energies introduced previously.

To further reduce the computational cost a so-called leapfrog algorithm is used.
As mentioned previously, every particle in the system is described using three positional coordinates, three momentum coordinates, and its corresponding energy.
With the leapfrog algorithm for each step of the MD we only calculate either the positinal coordinates or the momentum coordinates and "leap over" the other.
Periodic Box
MD Simulations are performed within a confined volume, called a unit cell.
This unit cell contains all particles that we simulate (i.e. protein,water,ligand)
This introduces the problem of boundary effects because atoms and molecules close to these boundaries of the unit cell have fewer interaction partners than those in the middle of it.
To avoid boundary effects at the edges of the unit cell we repeat the unit cell periodically.
Thus, the shape of the unit cell has to allow such that a regular space filling lattice of unit cells can be arranged.
In our study we used a truncated octahedron.
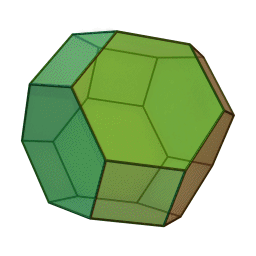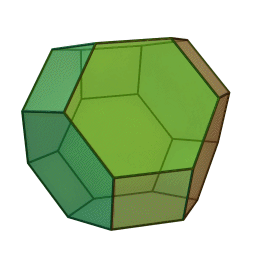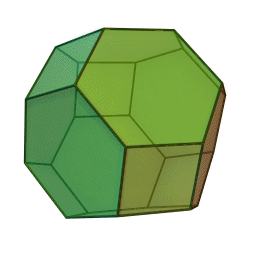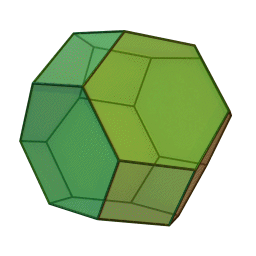
{kind=link}
Summary
- Based on Classical Physics
- No Electrons investigated
- No Bond cleavage or formation
- Fast Calculations and big Systems
Motivation
We went to great lengths to develop a workflow for metabolic engineering that utilizes the incredible power of directed evolution and is worthy of synthetic biology in the not so early 21st Century. With the very recent Nobel prize in chemistry towards directed evolution we think we have struck a nerve, and with Vibrio Natriegens this process can be streamlined even further. Traditional Chemistry with Synthesis as its supreme discipline and its implications in industry is one of the driving forces behind the modern wealth and is being improved on a daily basis. Synthetic Biology and in particular Metabolic Engineering as a chemical producing science can use that incredible knowledge and expand on it. Due to the completely different way of synthesis, we can mend the problems that classical synthesis is facing (e.g. natural products with many stereocenters, neccessary purification of products after most reaction steps) and synthesize compounds previously not able to be synthesized (e.g. Artemisinic acid) or ones that were too costly. Using metabolic engineering also has the advantage to produce chemical out of renewable resources while many chemicals right now are synthesized starting with fossil oil. To further improve this incredible opportunity to make more of the chemical space synthesizable in a cheap, easy and renewable manner we need to go beyond "mix and match" pathways and explore novel enzymatic reactions. According to (Erb et al.2017) metabolic engineering has been categorized in 5 different levels, depending on the methods employed. These levels and the corresponding metabolic space is displayed in Figure [1]. We tried to expand on what we already did in our metabolic engineering project and tap the huge advantages using novel pathways offer. We tried to enable a novel pathway by engineering an enzyme to catalyze a new reaction which corresponds to the 4th level of metabolic engineering.

Design of the binding pocket
The pathway we chose for our metabolic engineering efforts was - in our opinion - the best pathway that has been explored previously. But there are many more possible theoretical (Valdehuesa et al.2013) pathways with remarkable properties that have not been explored yet. The reason is most of the times that it involves one or more reactions with no known enzyme to catalyze them. One theoretical pathway is from a free energy standpoint much more favorable, but there is one step without a known enzyme to catalyze it. We performed an intense literature research and decided to try to build an enzyme capable of decarboxylating malate to 3HPA. Even with Vibrio Natriegens if we would try to engineer an enzyme to catalyze the wanted reaction using random mutagenesis it would take ages if it succeeds at all. That is why we decided to use a combination of in silico as well as wet lab methods to boost our chances of succeeding.
The pathway that we want to enable is displayed in Figure [2]. The step that has to be catalyzed is the decarboxylation reaction of malate to our final product, 3-hydroxypropionic acid ( 3HPA). As a start, we investigated the enzyme family of Carboxy-lyases (EC Number 4.1.1). We - in accordance to literature - were not able to find an enzyme that can catalyse this reaction.
However, there were some that we thought could help us to develope a binding pocket capable of decarboxylating malate.
One of those was acetolactate decarboxylase (ALD 4.1.1.5).
The important difference from its natural substrate to malate being that there is a carboxy group in β position (see Figure X).
In this enzyme with the help of this carboxy group a double bond is formed to an intermediate product (see Figure X) that we cannot form with malate as substrate. But the zinc cation that is used as a cofactor should be able to bind to malate in a similar way as it does with the natural substrate.
This could be a promising starting point, because we would be able to sustain a specific conformation of the substrate and alter the electronic structure of the substrate at the same time.
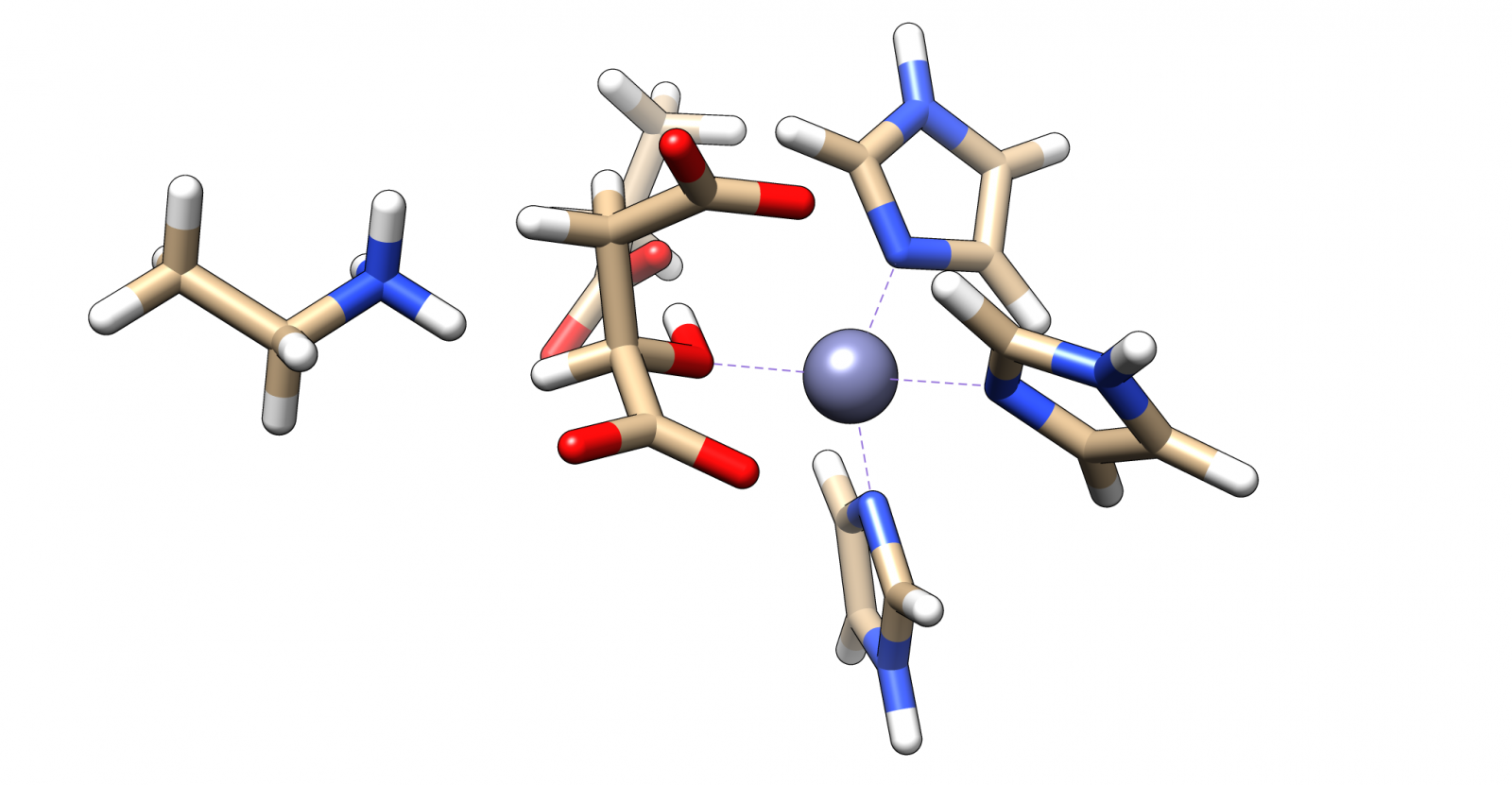
The complex of malate inside the ALD binding pocket is shown in Figure [3].
As you can see the zinc cofactor is bound by three histidines and the zinc binds to the malate (or the substrate analogue in the real crystal structure) with three interactions.
There is also another important residue close to this complex, Arg145.
After the double bond and with it the intermediate product is formed, this residue is protonating the intermediate to form the product.

Another enzyme with an enzyme mechanism that might help us find a way to catalyse this reaction is Orotidine 5'-phosphate decarboxylase (ODCase 4.1.1.23).
The reaction ODCase catalyses compared to the reaction of ALD and the one we want to catalyse is shown in Figure X.
In one impressive study conducted by (Courtney et al.2007) using
QM/MM
MD
simulations, the decarboxylation mechanism of ODCase has been investigated.
They have proposed a direct decarboxylation mechanism with theoretical values that are in good agreement with experimental values.
The reaction is split into two steps, first the decarboxylation and a simultaneous salt bridge between a lysine and the resulting carbanion.
After this, the lysine protonates the carbanion to yield the final product.
The most important difference between the substrate of ODCase and malate is, that the carbanion is stabilized through mesomeric structures (Figure X) in the former one whilst there is nearly no stabilization in the latter one.
The idea of our enzyme design is that we use the direct decarboxylation of ODCase and try to stabilize the carbanion with the cofactor of ALD.
With this plan, we need to engineer the pocket in a way that a lysine side chain can get to the carbon atom of malate that shall be protonated.
Even if this is achieved, the reaction is not automatically working since the transition state energy is probably far too high.
We need to calculate the transition state energy of our engineered systems and compare it to the literature to estimate the feasibility of our reaction.
As a start point we looked at all single point mutations to lysine that can be done where the protonated nitrogen of lysine has the possibility to get as close to the malate as needed for reprotonation. All Mutations investigated are displayed in table 1.
In the natural binding pocket of ALD there is an arginine residue that is used for reprotonation of the natural substrate.
Because of the possibility that this could disturb the lysine we mutated that in each binding pocket where it is not already mutated to a glycine.
| L34K | G57K | T58K | L62K |
|---|---|---|---|
| E65K | G64K | R145K | V147K |
in silico enzyme design
We developed a double modeling approach to investigate the whole system to the best of our ability. First, we try to investigate the reaction using quantum mechanical calculations (QM) and model the best possible system. Then we control how well this system is represented if we make certain mutations in the ALD with the help of molecular dynamic (MD ) Simulations.
Quantum mechanics calculations
First, we wanted to model the reaction that we try to catalyze using QM level calculations. We used density functional theory based method b3-lyp with different basis sets. With these calculations, we tried to get a further insight into the reaction coordinate and all corresponding energies, most importantly the activation energy of the reaction. The activation energy can be calculated as the difference between the energy of the educts and the transition state energy. The activation energy is crucial in the activity of the final enzyme and high activation energies correspond to low or no activity of the final enzyme. According to (Courtney et al.2007) the reaction is split into two steps. First, the decarboxylation happens and a salt bridge is formed between the positively charged lysine and negatively charged carbanion. In a second step one of the protons of the lysine is protonating the negatively charged carbanion and with that the reaction is complete. The first step of the reaction is the rate-limiting step of the reaction (Courtney et al.2007) and because of this, we decided to focus on it.
Setup of systems for calculation
As a start point for a structure we used the ALD crystal structure of (Marlow et al.2013) (PDB CODE 4BT3). From that, we extracted the position of the three zinc coordinating histidines, the zinc cation, and the substrate and changed the substrate to malate. We then built multiple differently binding pockets that are displayed in Table [2].
| Kind of Binding Pocket | Abbreviation used in Graphs | Residues/Molecules involved |
|---|---|---|
| Binding Pocket without Cofactor | Complex | Lysine, Substrate |
| Binding Pocket | Nor_1 | Three Histidines, Zinc cation, Lysine, Glutamate, Substrate |
| Binding Pocket pre-optimized | Nor_2 | Three Histidines, Zinc cation, Lysine, Glutamate, Substrate |
| Minimal Binding Pocket | Min | Three Histidines, Zinc cation, Lysine, Substrate |
| Binding Pocket with two lysine residues | 2ly | Three Histidines, Zinc cation, Lysine, Lysine, Substrate |
Because we wanted to resemble the binding pocket to the best of our knowledge we made a system where we kept Glu 253 and added a lysine close to the carbon that it shall protonate.
Later we used a pre-optimized structure of previous calculations and used this pre-optimized structure to build a minimal binding pocket where we removed Glu.
We also made one system with two lysine residues.
We will go into detail on why and how we designed this system when we explain the hypothesis.
As a start point we also used a structure of just malate and lysine.
The final systems are displayed in Figure BLA.
 a
a b
b c
c d
d
Results of QM Calculations
 A
A B
B C
C D
D
Just for the complex the activation barrier is 59.04 kcal/mol.
This is far over the free energy barrier of ODCase in the literature (15.54 kcal/mol (Courtney et al.2007)).
If we now take a look at the activation barrier with the normal binding pocket with the 6-31g* basis set (53.48).
This is not what we expected or wanted to see since this means the addition of the zinc complex that shall stabilize the carbanion only benefits the reaction with around 6 kcal/mol.
The transition states that we calculate are confirmed using frequency calculations.
If there is just one negative frequency calculated for a optimized structure, this means that it is a transition state.
The frequency can then be animated, to show the movement that is enforced by it.
An animation of the negative frequency of the minimal binding pocket transition state can be seen in Figure 6.
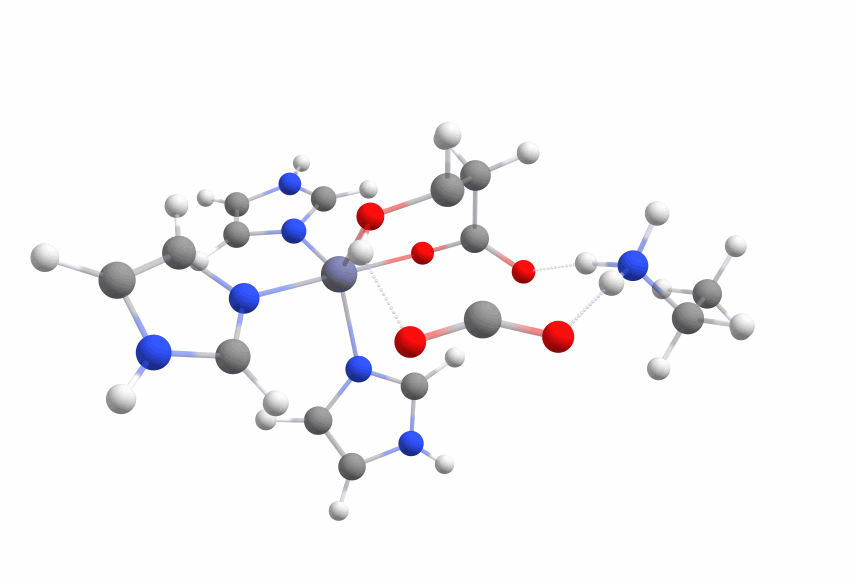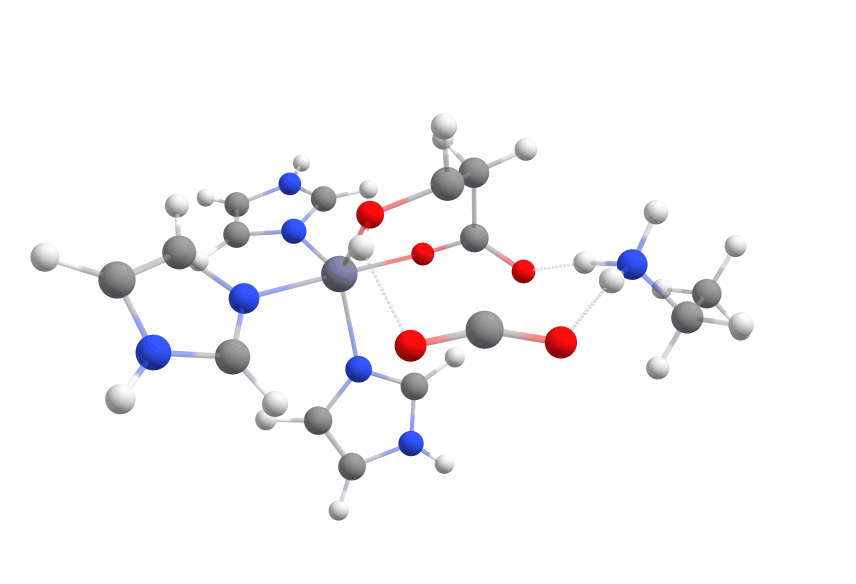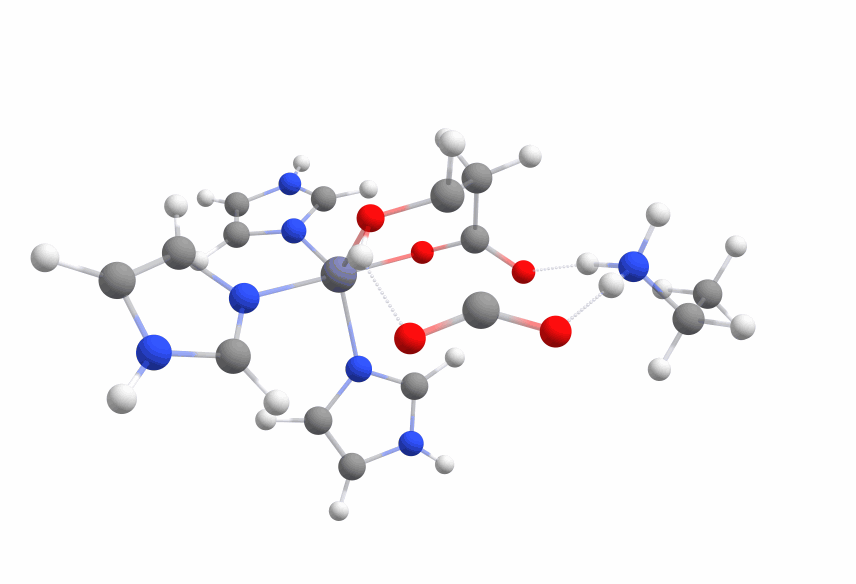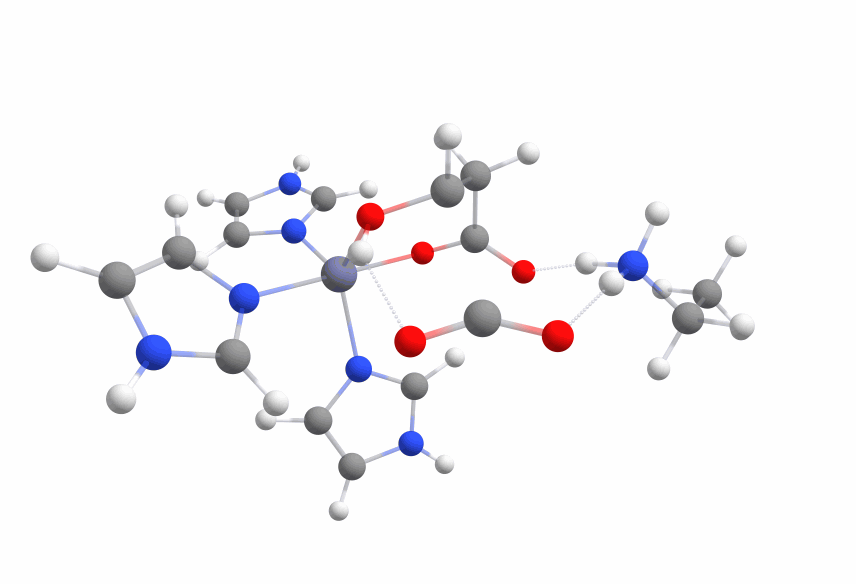
This was boosting our hope that if we introduce the correct changes to the binding pocket, we could change the electronic structure of the ligand in a way that reduces the activation barrier enough.
To use this knowledge we set up another system with two lysine residues, one interacting with both carboxy functions and one that shall protonate the carbanion in the hopes of lowering the activation energy even further.
Our expectations were subverted multiple times.
The activation barrier was slightly lower than before (~ 43 kcal/mol), but the second lysine was again not reprotonating the carbanion but interacting with the hydroxy group.
Far more interesting was the fact that the carbanion formed a covalent bond with the zinc cation with ca. 10 kcal/mol less energy than the transition state.
The optimized structure with the covalent bond between the zinc cation and the malate is displayed in Figure 8.
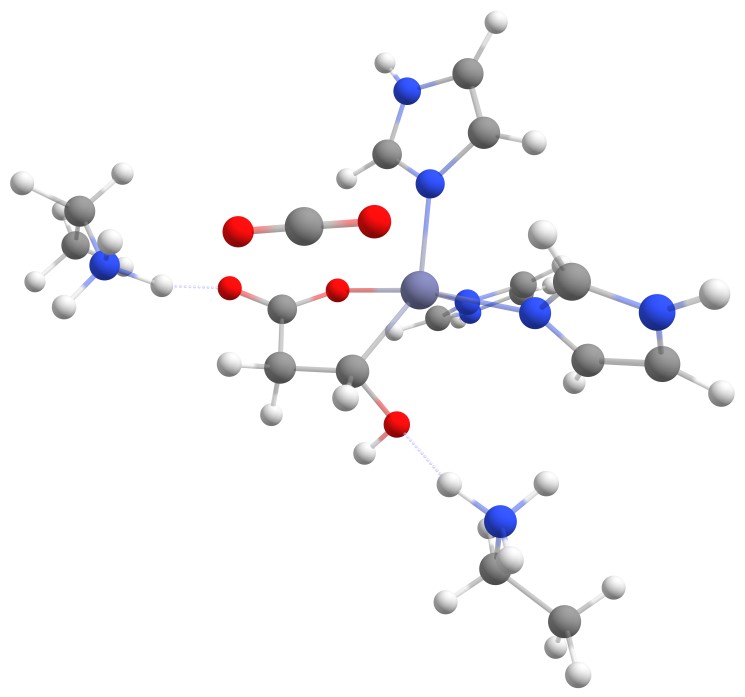
Molecular Dynamic (MD ) Simulations
To evaluate how well the system that we tried to engineer in the QM calculations is represented in the complete enzyme systems we performed MD simulations with in silico mutated enzyme versions. We performed 200 ns MD Simulations of all previously mentioned mutated systems as well as the wild-type enzyme with 3 replicas each. With the help of these MD simulations, we are able to evaluate how well the different mutations resemble the system that we designed for the QM calculations.
Setup of MD Simulations
For the MD simulations, we used the ALD crystal structure of [Reference] (PDB CODE 4BT3). We changed the substrate to malate and made the corresponding mutations for each system. Then we capped the termini of the enzyme, checked for missing residues and protonated all residues according to pH 7.0. We visually inspected the residues close to the binding pocket to make sure that all protonation states seem correct.
Results of MD Simulations
To evaluate the different systems that we did MD Simulations on we developed a mechanical descriptor.
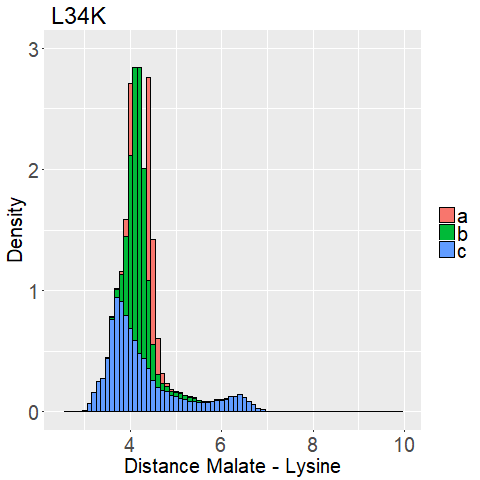
The most important thing in our case was the distance between the lysine side chain and the malate to see how well each variation resembles the structure that we assumed for the QM calculations.
We measured the distance between the lysine sidechains nitrogen atom and the carbon atom that shall be protonated of the malate for every frame of every MD Simulation.
An animation of one MD Simulation with the distance highlighted is shown in Figure 9.

 a
a b
b c
c d
d e
e f
f
This is very promising because it means that there is not only one potential position to introduce point mutations, which opens up further possibilities for enzyme design.
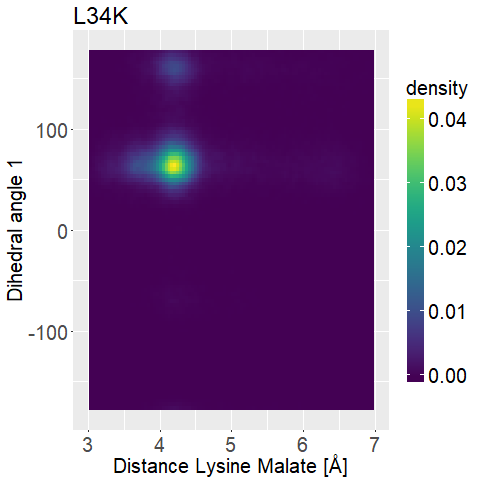
To further distinguish between the different variations we decided to look at two dihedral angles of the lysine sidechain to evaluate its flexibility.
We do this with the help of two-dimensional histograms, which basically means that we overlap two histograms of different properties to see if and how they correlate.
We substituted the normal counts that would be on the z-axis with densities to help compare the different graphs.
This means again that the integral over the complete 2d Histogram sums up to 1.
The optimal candidate should show some flexibility so it is not entropically inhibited, but should also show consistent small distances.
The results are displayed in Figure [FIGURE] and [Figure].
 a
a b
b c
c d
d e
e f
f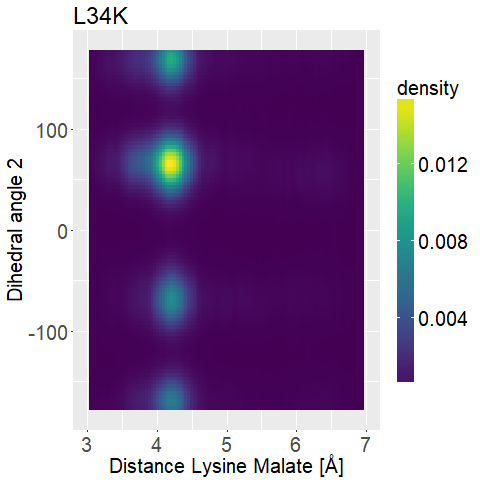 a
a b
b c
c d
d e
e f
fThere are multiple interesting things that we can conclude from these graphs. We can see that R145K shows very high densities, which means that the single state it is in is also very stable. Due to the restrained formation entropically this is not very favorable, which further declassifies this variation. T58K showed a stable conformation at a low distance, but we can also see that it is stable at a broad range of distances. L34K has multiple stable angles for dihedral angle 2, whilst having only one for dihedral angle 1 and a small and low distance range. If we take the normal as well as the 2d histograms into account, L34K seems the most promising of all of the different variations.
Wetlab
Summary
We have developed an in silico workflow to design a novel decarboxylase that with minor changes can be adapted for other carbon-carbon bond cleavage enzyme designs, de novo or not.
We predicted that the activation barrier for the reaction is too high for successful catalysis and this prediction was in agreement with our experiments.
Because of time and resources we were only able to look at single point and double mutations, but the reduction in the activation barrier when using lysine to interact with the carboxy functions showed that there are possibilities to change the electronical structure of the substrate in a meaningful way.
With the covalent bond between the zinc cation and the substrate we also showed that we can and should dare to think outside the box to find novel ways that could help to create a novel enzyme mechanism.
With the data obtained through our MD Simulations we showed that there are multiple positions in the binding pocket of ALD where we can introduce point mutations that interact with the substrate.
"I have not failed. I've just found 10.000 ways that won't work." - Thomas A. Edison
We strongly believe that it is possible to engineer a malate decarboxylase with the method that we developed.
Our data also shows that it might be worth it to think out of the box to do so and that there are multiple things that we can and should question about our catalysis idea.
In the coming years and decades, enzyme design will become more and more abundant, sophisticated and easy.
We would love to make a contribution towards this trend and do hope that we did this with our work.