Team:Tongji China/Demonstrate
Dry Lab

Model
Acknowledge:CPU_China. This part is made by Team CPU_China and thanks for their collaboration!
Phase 1. Bayesian statistics
We use Bayesian statistics to predict which type of mutation is most likely to product MHC strong binding peptides with the sum of the affinity of each mutation site and each allele type.Bayesian statistics is a theory in the field of statistics based on the Bayesian interpretation of probability where probability expresses a degree of belief in an event. The degree of belief may be based on prior knowledge about the event, such as the results of previous experiments, or on personal beliefs about the event. This differs from a number of other interpretations of probability, such as the frequentist interpretation that views probability as the limit of the relative frequency of an event after a large number of trials.
Bayes' theorem is a fundamental theorem in Bayesian statistics, as it is used by Bayesian methods to update probabilities, which are degrees of belief, after obtaining new data. Given two events A and B, the conditional probability of A given that B is true is expressed as follows:
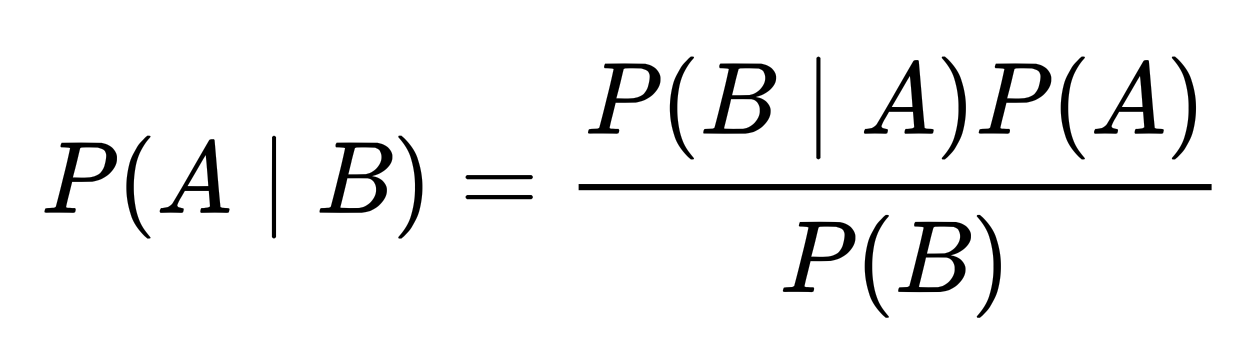
The probability of the evidence P(B) can be calculated using the law of total probability. If {A1, A2, …, An} is a partition of the sample space, which is the set of all outcomes of an experiment, then,
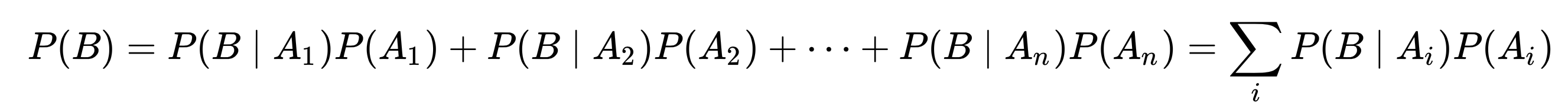
Phase 2. Prediction of mutations most likely to bind MHC I
We use Bayesian statistics to predict which type of mutation is most likely to product MHC strong binding peptides with the sum of the affinity of each mutation site and each allele type.The heat map below shows the sum of the affinity of each allele type and each mutation.
Figure.Model.1 Heatmap of the affinity of each allele type and each mutation.
From the heatmap above, we could know that the mutation sites at the bottom of the heatmap have big affinity amount, and some mutation sites at the middle show small sum of affinity. Considering the "affinity" presents the amount of peptides binding to a certain amount of MHC-I molicule, lower "affinity" means stronger binding to the MHC-I. So in that heatmap, if cell color is close to yellow, the mutation site with the allele of that cell may product MHC strong binding peptides. On the contrary if cell color is close to blue, the mutation site with the allele of that cell probabily can not product MHC-I binding peptides.
If a colorectal cancer patient is detected to have an immune response to our medicine, we can predict which mutation is playing the strongest role in cancer using this model. If a patient's mutation sites are already known, this model can also help predict which site can be the best one for peptide making for this certain patient which contributes to the individual therapy.
affinity_conseqeunce.csv Click to download the consequence file