Difference between revisions of "Team:SCU-China/modeling/algorithm"
| Line 88: | Line 88: | ||
line-height:2em; | line-height:2em; | ||
} | } | ||
| + | |||
| + | .sidebar { | ||
| + | width:20%; | ||
| + | float:left; | ||
| + | } | ||
| + | .sidebar ul { | ||
| + | font-size: 17px; | ||
| + | margin: 1em 0 0 1.8em; | ||
| + | z-index:1; | ||
| + | } | ||
| + | |||
| + | .sidebar ul li { | ||
| + | list-style: none; | ||
| + | text-indent: -1em; | ||
| + | } | ||
| + | |||
| + | |||
| + | .sidebar ul li a:hover { | ||
| + | color:#999999; | ||
| + | } | ||
| + | |||
.maincontent { | .maincontent { | ||
| − | + | width:860px; | |
| + | float:right; | ||
} | } | ||
| Line 164: | Line 186: | ||
<div class="content"> | <div class="content"> | ||
<div class="main"> | <div class="main"> | ||
| − | <div class="maincontent"> | + | <div class="sidebar "> |
| + | <ul> | ||
| + | <li><a href="orthogon">Orthogonality</a></li> | ||
| + | <li><a href="2018.igem.org/Team:SCU-China/modeling/prediction">Mismatch</a></li> | ||
| + | </ul> | ||
| + | </div> | ||
| + | <div class="maincontent" id="orthogon"> | ||
In our experiment, we need to construct a sgRNA sequence that is orthogonal to both the genome and the plasmid. | In our experiment, we need to construct a sgRNA sequence that is orthogonal to both the genome and the plasmid. | ||
The algorithm steps are as follows: | The algorithm steps are as follows: | ||
| Line 202: | Line 230: | ||
</ol> | </ol> | ||
<br /> | <br /> | ||
| − | </br></br> | + | </br></br> |
<div class="subtitle">References</div> | <div class="subtitle">References</div> | ||
| − | </br></br><hr style="height:1px;border:none;border-top:1px solid #555555;" /></br> | + | </br></br><hr style="height:1px;border:none;border-top:1px solid #555555;" /></br> |
<div class="block">[1] Bikard, D., Jiang, W., Samai, P., Hochschild, A., Zhang, F., & Marraffini, L. A. | <div class="block">[1] Bikard, D., Jiang, W., Samai, P., Hochschild, A., Zhang, F., & Marraffini, L. A. | ||
(2013). Programmable repression and activation of bacterial gene expression using an engineered | (2013). Programmable repression and activation of bacterial gene expression using an engineered | ||
crispr-cas system. Nucleic Acids Research, 41(15), 7429-7437.</div> | crispr-cas system. Nucleic Acids Research, 41(15), 7429-7437.</div> | ||
</div> | </div> | ||
| − | + | <div style="clear:both;"></div> | |
</div> | </div> | ||
</div> | </div> | ||
| − | |||
</div> | </div> | ||
| + | <div class="footer">SCU_China 2018 iGEM Team</div> | ||
</body> | </body> | ||
Revision as of 02:09, 18 October 2018

In our experiment, we need to construct a sgRNA sequence that is orthogonal to both the genome and the plasmid.
The algorithm steps are as follows:
- Sequence summary: E.coli genome is sequence α, with length m; All plasmid sequences that need to be orthogonal are spliced into a sequence β of length n.
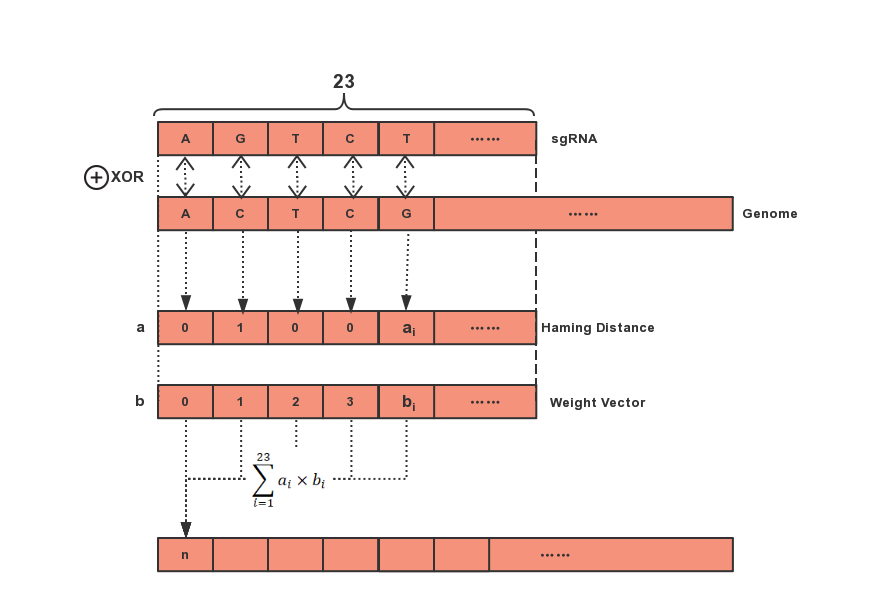
- Genome orthogonal screening: A randomly generated sgRNA sequence λ that ends in NGG together with all
23 consecutive sequences on sequence α are ruled as heterotopic or, and their total weighted scores
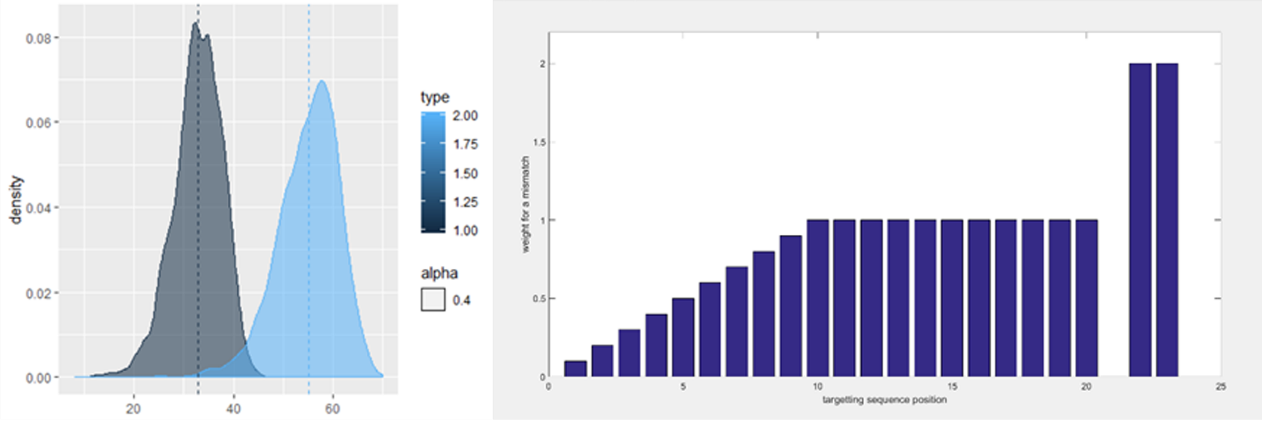
are obtained. Then reverse α and do the same thing. Eventually, we can get two score sequences of
length m-22. The distribution function with the total weight points in the entire sample space was
calculated in advance by means of parameter estimation, and then different threshold values of the
orthogonal exponential threshold μ_1were selected according to different orthogonality requirements.
The threshold value used in this experiment was 63 (90%). Retrieve two socre sequences.If there is a
score value below μ1, it is considered not to satisfy genomic orthogonality;if the conditions are met,
proceed to the next step. In addition, we used some empirical weight values - Weights 1 to 10 are assigned
at a time from 10 digits away from the PAM end,10 in the seed region;t he 10 sites in the seed region
assign an average value of 10; The 21st bit weight is 0,22 and 23 bit weight is 20.
- Plasmid orthogonal screening: Repeat algorithm in step 2 using the sequence from step 2 and sequence β. And remove the weight score of two plasmid spliced sequences that do not exist in the bacteria.The screening was done with threshold value μ_2 = 43.Record the filtered sequence.
- Repeat steps 1, 2, and 3 until the number of recorded sequences reaches 600.
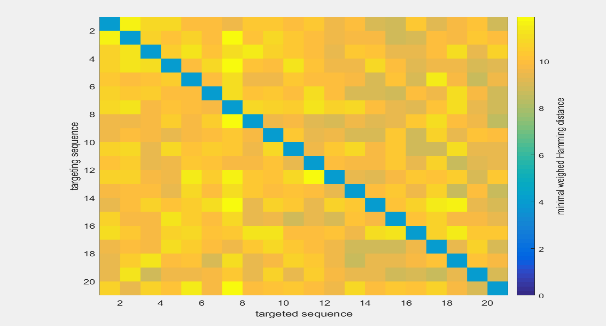
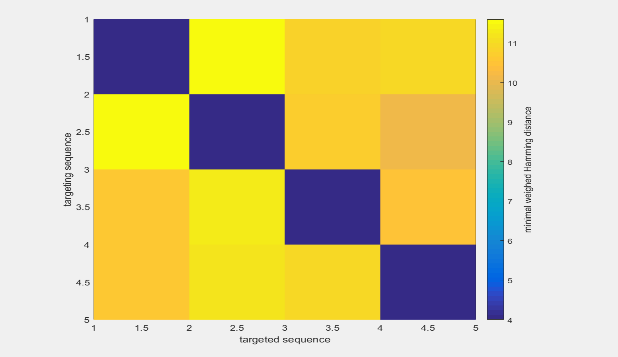
- Verify the orthogonality of all the obtained sequences among each other, and finally obtain the
20 sequences that are most orthogonal to the genome and plasmid. The result matrix obtained by mutual
verification is as follows:
Each pane shows the value of the orthogonality between two sequences.So it is clear we should choose the sequences on the top left.
All codes were written in Fortran and can be find here.
References
[1] Bikard, D., Jiang, W., Samai, P., Hochschild, A., Zhang, F., & Marraffini, L. A.
(2013). Programmable repression and activation of bacterial gene expression using an engineered
crispr-cas system. Nucleic Acids Research, 41(15), 7429-7437.