Team:Toulouse-INSA-UPS/Model
MOLECULAR MODELLING

Why Do We Want to Model Our Platform?
Our new molecular binding platform contains three binding sites: streptavidin (mSA2), a Carbohydrate Binding Module (CBM3a) and an unnatural amino acid, 4-azido-L-phenylalanine (AzF). These “heads” of our Cerberus are connected by flexible regions, composed of 30-50 amino acids each. These regions called linkers are described in the literature as being highly flexible and as disordered regions1;2.

Figure 1: General design of our Cerberus protein
For more information about our platform, visit the Description or Design pages.
As our linkers between domains are so flexible, it was possible that the CBM3a and mSA2 heads could be brought into contact. Interactions between the different molecular components of the platform could disturb their capacities to bind the target ligands. The spatial organisation of each component could also prevent the functionalization of our platform. In order to try to answer all these questions, we implemented multi-step and multi-level molecular modeling strategy.
First, we built a 3D structure model of our binding platform and we assessed its stability over time. We also evaluated the distance between the different domains and its variations, which provide information about the size of the ligands that can be bound to the platform. We studied the interaction of our binding platform with target ligands. Especially, large-scale conformational sampling and exploration methods were used to assess the conformational rearrangements of these 3D structure models (the binding platform, either free or in interaction with the target ligands) over time, hopefully maintaining their binding capacities.
On this wiki page, we detail the different steps of our molecular modeling strategy and our thought process behind the solutions that we chose to use.
Strategy
To meet all these challenges, we conceived a multi-level and multi-step molecular modelling workflow. Here is a graphical summary of this workflow:

Figure 2: Workflow of our molecular modelling approach
References
- Gunnoo et al., Nanoscale Engineering of Designer Cellulosomes, 2016
- E. Morag et al., Structure of a family 3a carbohydrate-binding module from the cellulosomal scaffoldin CipA of Clostridium thermocellum with flanking linkers: implications for cellulosome structure, 2013
Material and Methods
Available X-ray Data
3D structures of the CBM3a and mSA2 protein domains are available in the Protein Data Bank (PDB). We chose to use 4JO52 and 4JNJ3, both solved by X-ray crystallography, with a resolution of 1.98 and 1.90 Å respectively.
After obtaining these files, we faced two problems. First, the endogenous linkers of the CBM3a that we use to connect our heads together had never been resolved by biophysical methods, due to their flexibility and length. Secondly, 4-azido-L-phenylalanine (AzF) had never been modelled, in its native state or covalently bonded to another molecule. This process will be detailed further on in this page.
3D Structure Prediction
This did however present a complex challenge for the prediction methods used. Our protein is 366 amino acids in length, containing two protein domains structurally organised in protein secondary structures (CBM, mSA2) and two peptide linkers, one connecting the CBM and streptavidin and the other one free on the C-terminus of the protein. The linkers are known in the literature to be highly flexible1;2 and as Intrinsically Disordered Regions (or IDRs) and therefore their structures have never been successfully resolved by biophysical methods.
The three prediction software tools we chose to use were I-TASSER, Swiss Model and MODELLER. This allowed us to obtain a 3D structural model of our protein on which we could start calculations.
I-TASSER is an online platform hosted by the Zhang Lab (University of Michigan) that can perform 3D model protein prediction4. It computes it by searching reference templates in the PDB database through the LOMETS server, filling the unidentified regions by replica-exchange Monte Carlo Simulation. It then assembles the input structure to the 10 most probable models found on the database. It performs optimization of the structure and searches for protein domain enrichment in different databases such as Gene Ontology.
SWISS-MODEL service proposes a protein sequence homology based 3D modeling5. It performs sequence homology research through BLAST and on the SWISS MODEL Template Library to begin the structural assembly. If there is no match in the database, the algorithm performs a Monte Carlo technique to find the best conformation.
MODELLER is an software for protein 3D structure modeling. It uses homology for template reference but also implements a structure reference based prediction of the most potent conformation6.
Simulated Annealing
When dealing with a protein as large and complex as ours, 3D prediction approaches described above are not sufficient for obtaining an adequate structure. We then performed simulated annealing on the 3D model obtained through the previous approach. This process involves first a protein energy minimisation, then a series of heatings and coolings. This enables it to exit a local energy minimum and re-settle in a more global energy minimum.
Simulating Annealing was performed using sander, from the Amber16 suite. Amber is a suite of biomolecular simulation programs used both for generating parameters for molecules to be simulated and for simulating those molecules over time7. It was first released in the late 1970s and is consistently kept up to date and features a large range of tutorials and forums to help users. All simulations performed with Amber16 used the ff14SB force field for topology and parameters of standard amino acids in the protein...
The minimisation phase was performed over 5,000 cycles to find the lowest energy point, holding the streptavidin and CBM3a domains fixed.
Orthos was heated and equilibrated following these steps:
- 0 - 200ps: Heat from 100 K to 330 K
- 200 - 500ps: Equilibrate at 330 K
- 500 - 700ps: Cool from 330 K to 310 K
- 700 - 1000ps: Equilibrate at 310 K
Each of these was performed with an integration time of 2 femtoseconds.
IDR Conformational Sampling and Exploration
The challenge here was the complexity of the IDRs. During the previous phase of our study, we were faced with the limitations of classic protein modelling methods. These approaches generally search for secondary structures (helices and sheets) connected by short flexible connectors (3-10 residues), but when faced with a long region lacking in secondary structures, they fail to predict an appropriate structure.
To overcome this limitation, we therefore needed to find an innovative method well-suited to predicting the 3D conformation of long IDRs.
The LAAS, Laboratoire d'Analyses et d'Architecture des Systèmes, a French National Scientific Research Centre, developed original approaches for efficient large-scale molecular conformational sampling and exploration. These methods, recently developed by a colleague of our modelling supervisor and still in press, rely on the modelisation of molecular structures as polyarticulated mechanisms8. Based on this modelisation, efficient algorithms derived from robotics have been adapted to explore molecular rearrangements. These algorithms allow us to avoid expensive molecular modelling methods and to access macromolecular rearrangements, thus overcoming limitations of traditional approaches.
These methods have recently been extended to explore IDRs and generate realistic conformational ensembles, and are integrated into the Psf-Amc library developed at LAAS. By disregarding secondary structure and seeking simply the angles between amino acids in an IDR, their approach builds protein chains incrementally from N- to C-termini. A database of experimentally-determined angles between tripeptides is sampled for each step, and the angle selected in this manner is added to the chain, then checked for collisions.
Two strategies can be used. The first, Single Residue Sampling (SRS), considers each amino acid individually to find appropriate angles, ignoring the residues flanking it (except if it is followed by a proline). The second, Triple Residue Sampling (TRS), takes the neighbouring amino acids into account when selecting the angles to add to the chain. This does require additional constraints applied onto the selection, to respect the angles found when adding the previous amino acid. The TRS strategy requires more calculation time, but is better at finding partially structured regions in the protein chain8.
AzF Building and Parameterization
Incorporating an unnatural amino acid into a protein is a complex task not just for molecular biologists, but also for molecular modellers. Most protein prediction and modelling algorithms use predefined force field parameters for the 20 canonical amino acids, which simplify parameterization. Using AzF meant building the 3D structure and then generating specific parameters for it. Rather than go through this whole pipeline multiple times, we opted to construct it bonded with the DBCO-Fluorescein, the fluorophore that we were using in the wetlab. This proved harder to accomplish than originally planned.
A first 3D structure was built using Avogadro, an advanced molecular editor and visualiser9, from a 2D model of AzF-DBCO-fluorescein molecule generated by ChemDraw. Next, the parameters of the molecule were generated using the GAFF force field10 and different modules (antechamber, LeAP, parmchk) of the AMBER biomolecular software suite. The main difficulty here was to incorporate the functionalised AzF residue as a part of the main protein, which involves creating covalent bonds to the neighbouring amino acids.
Here, we needed to align the structure of our AzF residue with that of the phenylalanine near the end of the C-ter linker, remove the phenylalanine then add the AzF with all the correct bonds (and none of the wrong ones).
Biotin is a well known case study of ligand - receptor, so building and parameterizing it was easier to perform. Additionally, this did not require any new bonds in our protein, as the interaction is not covalent. Again, we used the antechamber force field of Amber16 to create the necessary files. Placing it into the correct position in the streptavidin binding site was carried out by aligning our streptavidin domain with the X-ray structure of the streptavidin-biotin complex (PDB: 4JNJ3).
Explicit Solvent Model
To consider the protein as it behaves in its environment, we decided to simulate our platform explicitly in its solvent. This means adding a great number of water molecules around it, using the TIP3P model, and calculating values for all of these new interactions, instead of simply simulating the general physical and chemical conditions of the solvent. Due to the great flexibility of our linkers, we needed to generate the box large enough to accommodate the full length of our Cerberus protein when these linkers are fully stretched out. We therefore left a minimum distance of 20 Å around our protein when generating the water box to contain it, in the shape of a truncated octahedron.
In total, this amounted to over 40,000 water molecules in our model, and in total 127,995 atoms with the protein. Incorporating this number of new atoms into our model meant adding millions, maybe even billions of new interactions.
The equilibration phase decreases the temperature of the protein and its solvent to allow it to settle back down into a local medium, usually a lower one than the previous minimum attained.
5 Na+ ions were also added to neutralise the protein.
This model represents the full Cerberus system. It features the unnatural amino acid incorporated into the C-terminal linker, functions added onto the two binding sites that we wished to explore and characterise and a complete simulation environment containing water molecules and sodium ions. We were then ready to prepare it for the molecular dynamics phase.
Molecular Dynamics
Preparation of molecular dynamics simulations consisted of initial minimization steps (steepest descent and conjugate gradient methods) where atomic positions of solute were first restrained using a harmonic potential. The force constant was then progressively diminished throughout the minimization procedure until a final unrestrained minimization step. We first minimised our system over 5,000 steps with restraints on the whole protein to minimise the solvent and ions, then reduced the restraints gradually over five minimisation cycles, for 1,000 steps each cycle. One final minimisation was performed with no restraints for 10,000 steps.
The minimization procedure was then followed by a slow heating to 310 K over a period of 0.1ns, with a moderate restraint placed on the protein. At the final required temperature, the system was equilibrated for 100 ps using constant temperature (310 K) and pressure (1 bar) conditions via the Berendsen algorithm with a coupling constant of 0.2 ps for both parameters. Along the equilibration, the restraints on the protein were gradually diminished. Electrostatic interactions were calculated using the Particle-mesh Ewald method with a nonbonded cutoff of 10 A. All bonds involving hydrogen were constrained with the SHAKE algorithm, allowing the use of 2 fs time steps to integrate the equations of motion.
Next came the production phase, where we can observe how the model behaves over a large period of time. Depending on the size of the system and the resources available, this phase can last from a few nanoseconds up to a few hundred ns. Due to the explicit solvent in our model and the size of our platform, we needed vast amounts of processing power to simulate it for a long time.
Thanks to CALMIP, a regional high performance calculation mesocentre, we were able to model our platform for a sufficient period and obtain useable results. We used 100,000 CPU hours on their servers for our simulations, generating over 85GB of data.
Two separate production phases were performed. The first involved our Cerberus protein in its water box, with no constraints on any region of the system. It ran for 120ns. The second featured a distance constraint between the sulfur atom of the biotin molecule and the alpha carbon of the nearby glycine 14 residue, to keep it within range of its associated binding site. This one ran for 80ns.
Both simulations were performed at constant temperature (310K) and pressure (1 bar) and with an integration time step of 2fs.
NAMD is a parallel molecular dynamics code designed for high-performance simulation for large systems11. NAMD was developed by the Theoretical and Computational Biophysics Group in the Beckman Institute for Advanced Science and Technology at the University of Illinois at Urbana-Champaign. It is based on Charm++ parallel object, and scales well on up to thousands of cores for the largest simulations. NAMD is compatible with the Amber force fields generated during the previous phases, it was therefore easy to reuse these parameters.
Simulations were performed on Amber16 for the minimisation, heating and equilibration phases of the dynamics workflow, and NAMD for the production phase due to its higher multiprocessor capacities. The first three steps were run on 80 processors in parallel, whereas production was performed on 1000.
References
- Gunnoo et al., Nanoscale Engineering of Designer Cellulosomes, 2016
- E. Morag et al., Structure of a family 3a carbohydrate-binding module from the cellulosomal scaffoldin CipA of Clostridium thermocellum with flanking linkers: implications for cellulosome structure, 2013
- D. Demonte et al. , Structure-based engineering of streptavidin monomer with a reduced biotin dissociation rate, 2013
- J Yang et al. , The I-TASSER Suite: Protein structure and function prediction, 2015
- A. Waterhouse et al., SWISS-MODEL: homology modelling of protein structures and complexes, 2018
- B. Webb, A. Sali, Comparative Protein Structure Modeling Using Modeller, 2016
- R. Salomon-Ferrer, D.A. Case, R.C. Walker, An overview of the Amber biomolecular simulation package, 2013.
- A. Estana, N. Sibille, E. Delaforge, M. Vaisset, J. Cortes, P. Bernado, Realistic ensemble models of intrinsically disordered proteins using a structure-encoding coil database, in press (submitted Sep 2018).
- M. Hanwell et al., Avogadro: An advanced semantic chemical editor, visualization, and analysis platform, 2012
- J. Wang, Development and Testing of a General Amber Force Field, 2004
- James C. Phillips et al., Scalable molecular dynamics with NAMD, 2005
Results
3D Structure Prediction
Only the 3D prediction software Modeller provided us with a satisfactory structure, most likely due to its improved de novo prediction capabilities and the usage of constraints on the final model. The other two algorithms struggled to suitably resolve the position of the linkers.

Figure 3: 3D structure of Orthos obtained from Modeller. In green, CBM3a, in red, mSA2, and yellow and blue the N-terminal and C-terminal linkers respectively. This colour code is used throughout this page.
We can see that the linkers seem to tangle together quite significantly. However, our two heads keep their tertiary structure, are an adequate distance apart, and positioned so that their binding sites remain available.
This is a satisfying first step, however this prediction is not sufficient on its own due to the protein's size and complexity. Simulated annealing is a good method to confirm the conformation of the linkers and the final structure of our heads by exploring the energetic landscape of our protein in greater detail.
Simulated Annealing
This phase was conducted on the best conformation obtained from Modeller. After completing the minimisation and successive heating and cooling phases of our platform, we obtained this structure:

Figure 4: 3D structure of Orthos obtained after simulated annealing
We can see that once again, the linkers are considerably tangled, but here again the complex heads keep their structure and general positions. We know that these peptidic linkers present a great flexibility and we should see more variability in the conformations adopted. This is important to know so as to better understand the binding possibilities of our heads, and most importantly whether the spatial disposition of our platform allows us to functionalize all of these heads simultaneously. To investigate the possible conformations further, we continued our approach with the robotics inspired methods.
IDR Conformational Sampling and Exploration
Both the SRS and TRS methods were applied to the minimum energy conformation of Orthos obtained previously, generating 1,000 structures each.
Thanks to this large scale sampling of possible conformations, we conducted a statistical analysis studying the distance between the alpha carbon of the phenylalanine 366 and the alpha carbon of the glutamic acid 32 of the streptavidin binding site, as well as the global Root Mean Square Deviation (RMSD) of the protein.
The RMSD is a measure equal to the sum of the geometric distances between each atom of a molecule, compared to the initial conformation, aligning each frame to this to mask the translational and rotational variations. Through this, we can study the conformational variability of our protein. We calculated it here on the peptidic backbone of the protein.

Figure 5: Various positions of the mSA2 domain (in red) in relation to the CBM3a (in green) as calculated by the SRS strategy developed by the LAAS, showing the distance between the mSA2 binding site and AzF alpha carbon (dotted line, distance in Å), animated


Figure 6: Various positions of the mSA2 domain (in blue or red) in relation to the CBM3a (in green) as calculated by the SRS strategy (left) and the TRS strategy (right), static
The figures shown directly above (Figure 6) were generated by loading 5 different structures calculated by the LAAS, then aligning the CBM3a domain of each of them. As you seen on the figures, both of these simulations show the range of positions that the streptavidin head can take in relation to the CBM3a, also demonstrating the high flexibility of the linkers.
With these data extracted, we can move on to the statistical analysis of the measurements made.


Figure 7: Distribution of the mSA2 binding site - AzF distance for each conformation calculated by the SRS strategy (left) and TRS strategy (right)


Figure 8: Distribution of the global RMSD for each conformation calculated by the SRS strategy (left) and TRS strategy (right)
Shown above are the distribution plots of both the mSA2 - AzF distance (Figure 7) and RMSD (Figure 8) from both robotics based simulations. We can see that the distance peaks at around 79 Å for the SRS strategy and 70 Å for the TRS strategy, and 21 - 24 Å for the RMSD.
This study of the mSA2 and AzF distance is a promising result regarding the spatial disposition of the heads in relation to each other. We see that the distance rarely falls below 25 Å or above 125 Å, indicating that we should be able to graft most compounds to these heads. The distribution of the RMSD also shows that our platform does not radically lose its structure, but also confirms the great diversity of the possible positions of the linkers and their associated heads.
With these data, we selected the most represented overall conformation of our protein, and therefore the most probable, to continue our strategy. We wished to observe the protein's behaviour and evolution temporally, now that we had studied its possible conformations stochastically.
Molecular Dynamics

Figure 9: Restrained biotin simulation, showing the distance between the mSA2 binding site and the AzF alpha carbon (dotted line, distance in Å)


Figure 10: Free biotin (left) and restrained biotin (right) simulations, showing the secondary protein structures.
Warning: These files are very large and will take a long time to load. They may also fail to load, in which case reloading the page is necessary.
Above, you can see a video generated from the structural data generated by taking snapshots every 0.5ns along our simulation. By observing its general structure, we can see that the linker sections are indeed very flexible but seem to adopt some preferred positions.
For example, the N-terminal linkers sticks to one side of the CBM3a domain due to hydrogen interactions. We can also see the biotin molecule exiting its binding site after around 15ns.
We also tracked the distance between the alpha carbon of the azidophenylalanine residue and the glutamic acid 32 residue. Extracting the raw numbers for each frame displayed allowed us to study its evolution closely, as you can see on these plots:

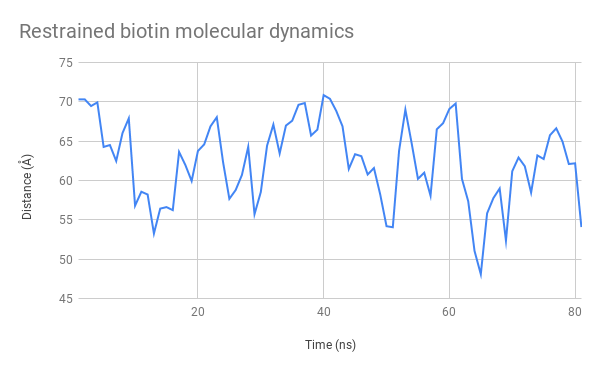
Figure 11: Evolution over time of the distance between the mSA2 binding site and AzF alpha carbon for the free biotin (left) and restrained biotin (right) simulations
The graphs (Figure 11.) indicate that this distance stays between 45 and 70 Å. This is a very satisfactory result, showing that we can design uses for our platform both with separate functions used independently and with two halves of a molecule that need to be assembled to produce a function. We had also considered using FRET to test this distance experimentally, which is now possible seeing as the distance between these two heads remain at an appropriate distance to observe interactions of that nature.
By selecting only specific residues, we can measure the variability of certain regions of our platform through the RMSD value, calculated on the whole protein, including the side chains this time.

Figure 12: Evolution of the RMSD of the different domains of our Cerberus protein over time: N-terminal linker in yellow, mSA2 in red and CBM3a in green
The structured domains keep their stability over time, with the RMSD of the CBM3a staying at around 2 Å throughout the simulation, and the streptavidin at around 4 Å.
The N-terminal linker however shows great flexibility, never keeping the same position during the time period studied here, with an RMSD peaking at close to 60 Å. The C-terminal linker presents a similar behaviour, with peaks at around 40 Å, it is not shown here for clarity’s sake.
This confirms that what we designed to be stable remains stable, and what was designed to be flexible remains flexible.
Conclusion
Thanks to these results, we are able to determine through multiple methods that out molecular binding platform behaves as planned when we designed it. Using the LAAS’ innovative robotic inspired methods, we overcame the challenge presented by the Intrinsically Disordered Regions. This novel approach circumvented the limitations that classic modelling software encounters and allowed us to progress in our project.
By measuring the RMSD of each domain of our protein and following their positions over the duration of our simulations, we can confirm that our linker regions are too flexible to resolve a definite conformation. Despite this extreme variability, we never observed entanglement between them during this simulation, nor did we see them bring the binding sites of our domains into contact. With this information, we can also be sure that the linkers shouldn't adopt a conformation where these binding sites become unavailable to their ligands.
Although we observe that the biotin molecule exits the streptavidin docking site during the molecular dynamics simulation, this occurs quite often in protein molecular modelling and is not a great source of concern for the viability of our platform. It is important to remember that all of these data are obtained through mathematical approximations, and that it is important to verify them in situ.
Finally, tracking the distance between the two distal heads showed that we could indeed attach medium to large functional molecules to these heads without risking too many unwanted interactions. However, due to the fact that they remain within 100 Å of each other, we could still imagine placing functions on the heads designed to interact with each other, for example to subunits of a protein that meet and activate under certain conditions.
No dogs were harmed over the course of this iGEM project.
The whole Toulouse INSA-UPS team wants to thank our sponsors, especially:









And many more. For futher information about our sponsors, please consult our Sponsors page.
The content provided on this website is the fruit of the work of the Toulouse INSA-UPS iGEM Team. As a deliverable for the iGEM Competition, it falls under the Creative Commons Attribution 4.0. Thus, all content on this wiki is available under the Creative Commons Attribution 4.0 license (or any later version). For futher information, please consult the official website of Creative Commons.
This website was designed with Bootstrap (4.1.3). Bootstrap is a front-end library of component for html, css and javascript. It relies on both Popper and jQuery. For further information, please consult the official website of Bootstrap.