Difference between revisions of "Team:SKLMT-China/Model Process"
Zhaowenxue (Talk | contribs) |
Zhaowenxue (Talk | contribs) |
||
| Line 42: | Line 42: | ||
</span> | </span> | ||
<p>We encode each three-base sequence with quaternary number(A,T,C,G represents quaternary number 0,1,2,3 ), and by running a C++ program (the whole code is shown in appendix), we get a vector with 64 dimensions from AAA to GGG, which calculates the frequency of appearance for each type in DNA sequence.</p> | <p>We encode each three-base sequence with quaternary number(A,T,C,G represents quaternary number 0,1,2,3 ), and by running a C++ program (the whole code is shown in appendix), we get a vector with 64 dimensions from AAA to GGG, which calculates the frequency of appearance for each type in DNA sequence.</p> | ||
| − | <p>After encoding, all DNA sequences are transformed into a vector with 64 dimensions. The entire data is stored in the document < | + | <p>After encoding, all DNA sequences are transformed into a vector with 64 dimensions. The entire data is stored in the document <latin>“data.xlsx”</latin>. For example, the vectors of promoters ampC and araA are shown as follows:</p> |
<span class="image fit"> | <span class="image fit"> | ||
<img src="https://static.igem.org/mediawiki/2018/2/2a/T--SKLMT-China--codedvectorschematictable.png" alt="Table 1. coded vector schematic table" /> | <img src="https://static.igem.org/mediawiki/2018/2/2a/T--SKLMT-China--codedvectorschematictable.png" alt="Table 1. coded vector schematic table" /> | ||
| Line 49: | Line 49: | ||
<p>At the end of the encoding step, we get an 25*64 matrix which reflects the features of these DNA sequences of each promoters. This encoding method has deep internal connection with the characteristics of DNA sequence, and it simultaneously contains the sequential relationship and details of DNA sequence. With this matrix, a mathematical model can be established.</p> | <p>At the end of the encoding step, we get an 25*64 matrix which reflects the features of these DNA sequences of each promoters. This encoding method has deep internal connection with the characteristics of DNA sequence, and it simultaneously contains the sequential relationship and details of DNA sequence. With this matrix, a mathematical model can be established.</p> | ||
<h3 class="title">Model establishment and solution</h3> | <h3 class="title">Model establishment and solution</h3> | ||
| − | <p>In order to simplify the problem, we assume that the connect between matrix and promoter strength is linear, in other words, the vector | + | <p>In order to simplify the problem, we assume that the connect between matrix and promoter strength is linear, in other words, the vector x exists when equation is satisfied.</p> |
<p>Now, through a lot of experiments, we have measured a total of 24 values, and all twenty-two valid values are shown below. Each data is the average of the results of three parallel experiments.</p> | <p>Now, through a lot of experiments, we have measured a total of 24 values, and all twenty-two valid values are shown below. Each data is the average of the results of three parallel experiments.</p> | ||
Revision as of 01:20, 16 October 2018
Background
We have built a promoter library of inner promoters with various strength in
1.To facilitate the promoter transformation of pseudomonas fluorescence in new site;
2.To reveal the correlation between promoter weights and their strength;
4.To improve the parameter setting of the promoter strength prediction in the species outside the large intestine with the method of position weight;
5.To provide reference for other microbe promoter strength prediction modeling.
Assumptions
1. It is assumed that the promoter strength is only related to the core DNA sequence.In other words, the DNA sequence can uniquely determine the promoter strength.
2. It is assumed that the laboratory environment has no impact on the test results.In other words, our test data can fully reflect the promoter strength.
3.It is assumed that there is a simple monotonic relationship between the obtained fluorescence data and the promoter strength: the larger the fluorescence value is, the stronger the promoter can be considered.
Modelling Process
DNA Sequence Encoding
The 5’-3’ region includes 70bp DNA information in each promoter. Currently, we have got 25 promoter sequences. We need to encode these 70 bases in order to establish a mathematical model. Notice that there’re only four types of bases(A,T,C and G),and calculating the numbers of each type is not enough to reflect interaction between adjacent bases.[2] Thus, we consider 3 continuous bases
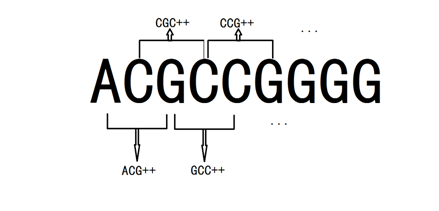
We encode each three-base sequence with quaternary number(A,T,C,G represents quaternary number 0,1,2,3 ), and by running a C++ program (the whole code is shown in appendix), we get a vector with 64 dimensions from AAA to GGG, which calculates the frequency of appearance for each type in DNA sequence.
After encoding, all DNA sequences are transformed into a vector with 64 dimensions. The entire data is stored in the document
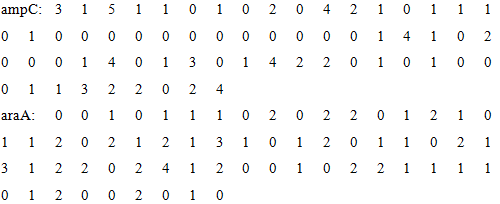
At the end of the encoding step, we get an 25*64 matrix which reflects the features of these DNA sequences of each promoters. This encoding method has deep internal connection with the characteristics of DNA sequence, and it simultaneously contains the sequential relationship and details of DNA sequence. With this matrix, a mathematical model can be established.
Model establishment and solution
In order to simplify the problem, we assume that the connect between matrix and promoter strength is linear, in other words, the vector x exists when equation is satisfied.
Now, through a lot of experiments, we have measured a total of 24 values, and all twenty-two valid values are shown below. Each data is the average of the results of three parallel experiments.