Difference between revisions of "Team:SKLMT-China/Results"
Zhaowenxue (Talk | contribs) |
Zhaowenxue (Talk | contribs) |
||
| Line 18: | Line 18: | ||
<p>The promoter intensity level corresponding to the data is as follows:</p> | <p>The promoter intensity level corresponding to the data is as follows:</p> | ||
<span class="image fit"> | <span class="image fit"> | ||
| − | <img src="https://static.igem.org/mediawiki/2018/8/89/T--SKLMT-China--promterleveleqution.png" alt=" " | + | <img src="https://static.igem.org/mediawiki/2018/8/89/T--SKLMT-China--promterleveleqution.png" alt=" " /> |
</span> | </span> | ||
| Line 26: | Line 26: | ||
<span class="image fit"> | <span class="image fit"> | ||
<img src="https://static.igem.org/mediawiki/2018/6/6c/T--SKLMT-China--promoterstrengthfig.png | <img src="https://static.igem.org/mediawiki/2018/6/6c/T--SKLMT-China--promoterstrengthfig.png | ||
| − | " alt=" Fig.1 The strength level of different promoters" | + | " alt=" Fig.1 The strength level of different promoters" /> |
</span> | </span> | ||
Revision as of 10:31, 17 October 2018
experiment Results
promoter library construction
Through our wet lab work, we have got 23 promoter strength data. The measured values are as follows:

The fluorescence from the luciferase gene without a promoter and from
Nowadays, the focus in metabolic engineering research is shifting from massive overexpression and inactivation of genes towards the model-based fine tuning of gene expression. In other words, being able to rationally designing a promoter would be extremely profitable in the context of a model-based metabolic engineering. Our project therefore attempts to link the promoter sequence to its strength. To this end, modelling strategies have been applied. (To learn more, please read our Model )
By solving the matrix sparse solution algorithm, we can conclude that there is indeed a linear relationship between the total 64 data of AAA-GGG and the promoter strength. Notice that we used merely 22 sets of data to approximately solve the sparse solutions of 64 equations with a fitting precision higher than 95%, therefore, when we provide as much data as possible, the fitting precision of the model will greatly increase.
We notice that there is a significant difference in the magnitude of the measurements between our group and the other groups. In order to better contribute our results to other teams, we will use the magnitude of our measurements and classify the promoters by numerical size.
The promoter intensity level corresponding to the data is as follows:
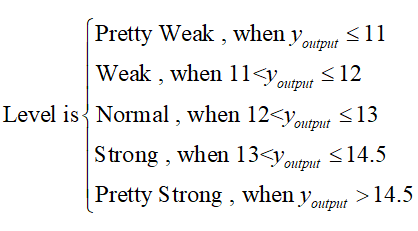
Using this standard, we quickly categorized 23 known promoters:
