Difference between revisions of "Team:Valencia UPV/Model"
Joancasado (Talk | contribs) |
|||
| Line 153: | Line 153: | ||
<h3>Models & Experiments</h3> | <h3>Models & Experiments</h3> | ||
<p><a href=""></a> | <p><a href=""></a> | ||
| − | The development of <b>new and simple mathematical models</b> has been one of the essential bases of the Printeria project. The ODE models offer a <b>multitude of applications</b>: describing the basic biochemical reactions of the cell, to <a href="#charact" class="inner-link">characterizing</a> the parts of our Printeria kit by means of different experiments, and elaborating <a href="#simtool" class="inner-link">new tools</a> that facilitate the user learn about Synthetic Biology. | + | The development of <b>new and simple mathematical models</b> has been one of the essential bases of the Printeria project. The ODE models offer a <b>multitude of applications</b>: describing the basic biochemical reactions of the cell, to <a href="https://2018.igem.org/Team:Valencia_UPV/Experiments#charact" class="inner-link">characterizing</a> the parts of our Printeria kit by means of different experiments, and elaborating <a href="#simtool" class="inner-link">new tools</a> that facilitate the user learn about Synthetic Biology. |
</p> | </p> | ||
<p> | <p> | ||
Revision as of 01:07, 18 October 2018


Do you think it is possible to mathematically describe a cell? Would you like to know the possibilities that modeling offers you?
One of the fundamental bases of Printeria has undoubtedly been mathematical modeling. Thanks to the development and application of new mathematical models, it is possible to quantify the expression of proteins in cells, and therefore characterize through different experiments the parts designed by Printeria. From the Printeria Modeling team, we intend to reach different goals:
Design simple mathematical models based on differential equations that describe the biochemical processes of a cell. With them, we can simulate the different genetic circuits that Printeria allows us to build.
Develop a Simulation Tool that allows the user to visualize a prediction of the results of their experiment before running it in Printeria.
Optimize model parameters to match simulation results to experimental data obtained from Printeria constructions.
Characterize the parts of our Part Collection from the optimization results and provide the user with all the information about the Printeria kit.
Although in the development of the project we have dealt with all these aspects, all of them have a single purpose: demonstrate the importance and many applications of describing in a mathematical way the biological processes that take place inside the cell.
Models & Experiments
The development of new and simple mathematical models has been one of the essential bases of the Printeria project. The ODE models offer a multitude of applications: describing the basic biochemical reactions of the cell, to characterizing the parts of our Printeria kit by means of different experiments, and elaborating new tools that facilitate the user learn about Synthetic Biology.
In Printeria Modeling team, we have grouped the models designed in two fields: constitutive expression models and inducible expression models. We have also established an experimental protocol and a multi-objective optimization protocol in order to contrast theoretical and experimental results. With them, we can describe practically all the cells modified with Printeria.
Want to find out more about how we did it?
Modeling process
At the beginning of the design of any mathematical model, we have started from a cell scheme in which all the biochemical reactions happen. From the reactions, a set of equations is inferred. Each of these equations describe the temporal evolution of the main biochemical species in the cell (DNA, RNA, proteins and transcription factors), and depend on a set of parameters with a physical meaning.
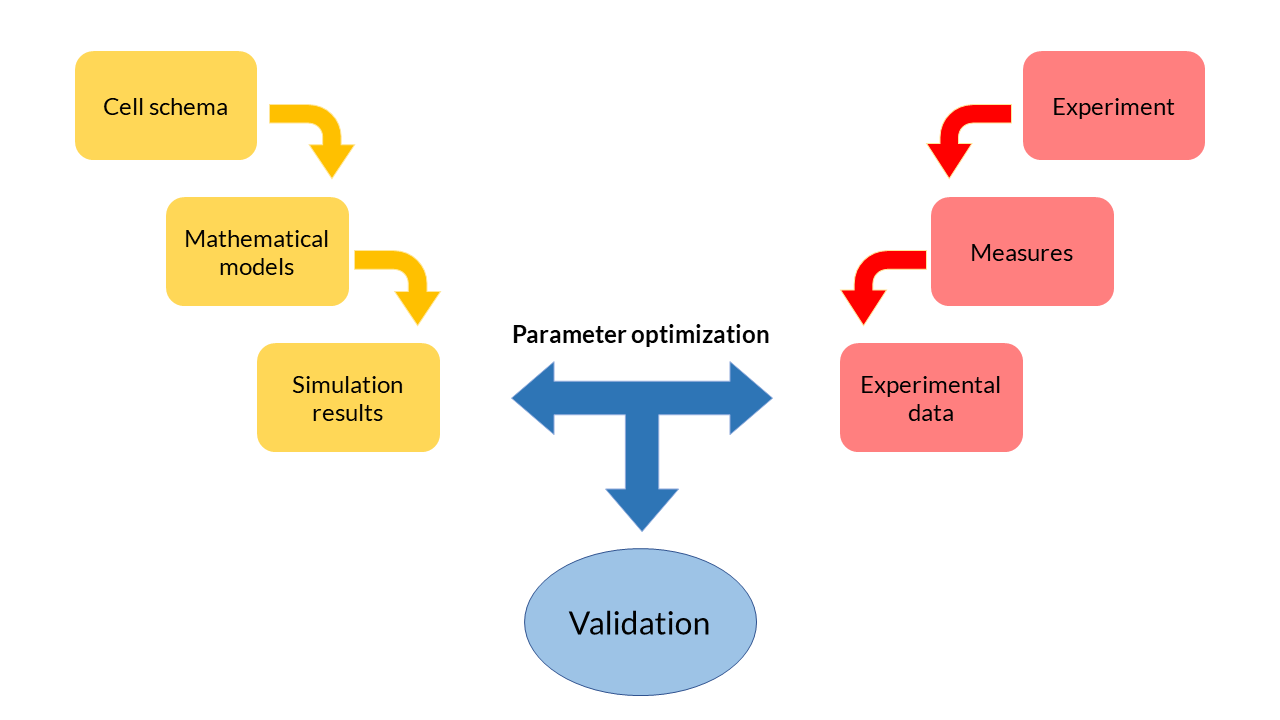
Modeling process schema.
Because they are ordinary differential and generally non-linear equations (ODE), mathematical models are simulated using software tools such as MATLAB. The results obtained from the simulation reflect the evolution of the concentration of biochemical species over time. These theoretical results can be contrasted with the experimental data obtained in the laboratory and thereby adjust the parameters. The ODE model fits the data in an optimal way. This process, called multiobjective parameter optimization, is the process that allows us to validate our models and see if they respond to what happens inside the cells.
The development of the set of mathematical models of the genetic circuits printed by Printeria, we have prioritized simplicity over complexity. A more complex model may be more precise, but it requires a large number of parameters whose value is oftenly unknown. Therefore, our models are reduced order but rigorous deterministic models , where their parameters take a concrete, non-probabilistic value.
Constitutive expression models
Constitutive expression models are those in which protein expression is not regulated. The gene that encodes a protein does not depend on any transcription factor, so it will continuously transcribe messenger RNA molecules, and then translation of the protein will be unregulated.
Model design
A simple scheme that summarizes the cellular transcription and translation processes in a constitutive expression model is shown in the following Figure. We only consider as biochemical species involved in reactions to mRNA and our protein of interest (PoI).
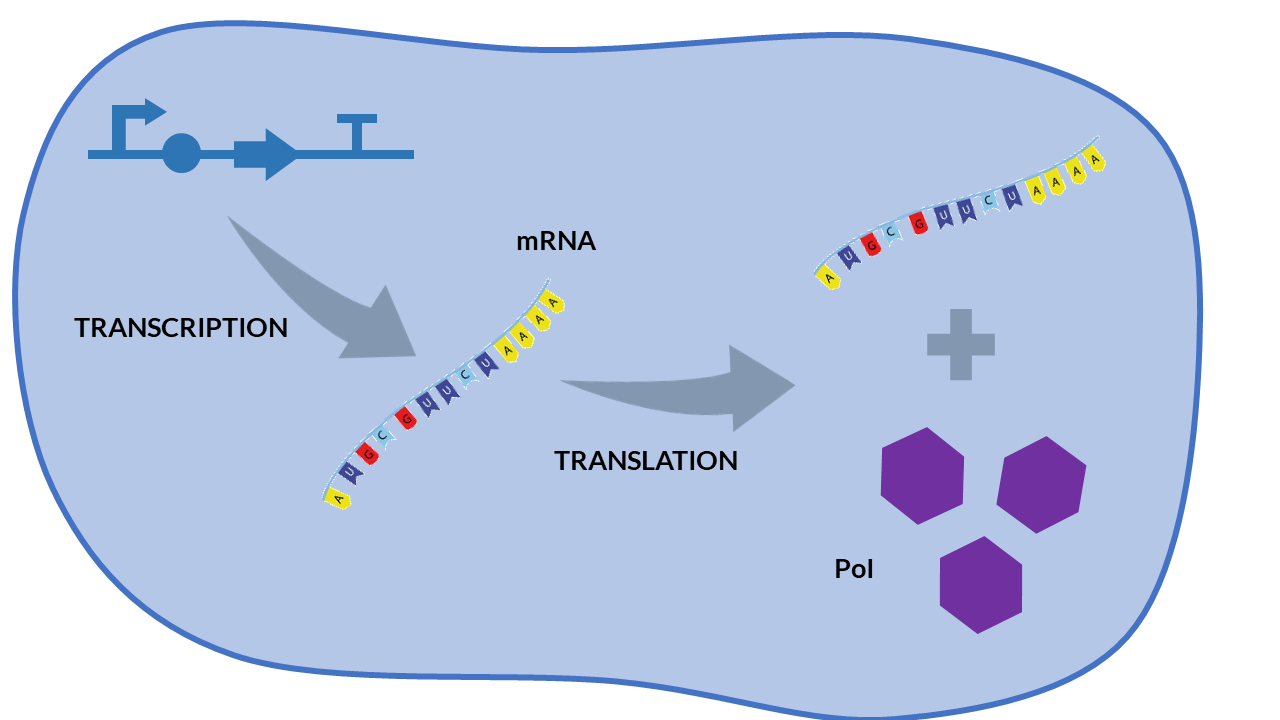
Constitutive expression model. Cell schema.
From the cell schema we can deduce the following biochemical reactions.
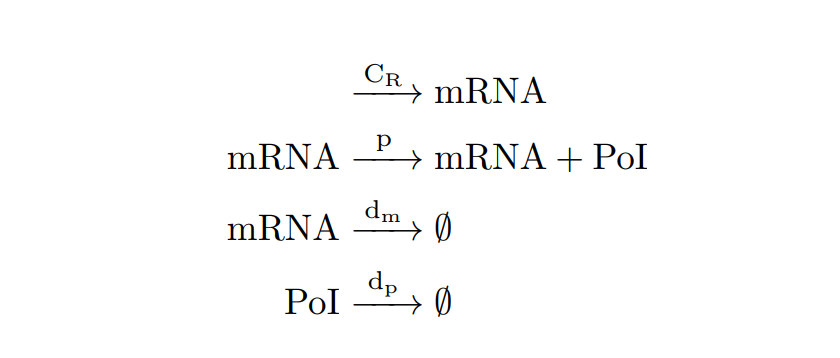
Constitutive expression model. Biochemical reactions.
Parameter |
Description |
Units |
Value |
|---|---|---|---|
CR |
Constitutive transcription rate is the transcription rate KR times the mean plasmid copy number in cell cn. In our case, we are using the pMBI replication origin, so cn ∼ 500, and CR = KR·cn |
molecules.min-1 |
|
p |
mRNA translation rate |
min-1 |
2.38 [2] |
dm |
mRNA degradation rate |
min-1 |
0.247 [7] |
dp |
PoI degradation rate |
min-1 |
0.156 [5] |
μ |
Dilution rate |
min-1 |
0.017 [5] |
Kmax |
Maximum growth capacity |
cells |
1.6·108 [5] |
Constitutive expression model. Model parameters obtained from literature.
With the reactions and approximations already established, we apply the Law of Mass Action kinetics[1] (LMA) to deduce the differential equations. The LMA establishes that the variation of the species resulting from a reaction is proportional to the product of the reactants. In our case, we also take into account an ODE for the cell growth. The resulting ODE model and the main biochemical species are shown below.
Variable |
Biochemical species |
Units |
|---|---|---|
n1 |
mRNA |
Molecules |
n2 |
PoI |
Molecules |
n3 |
Number of cells |
Cells |
Constitutive expression model. Biochemical species.
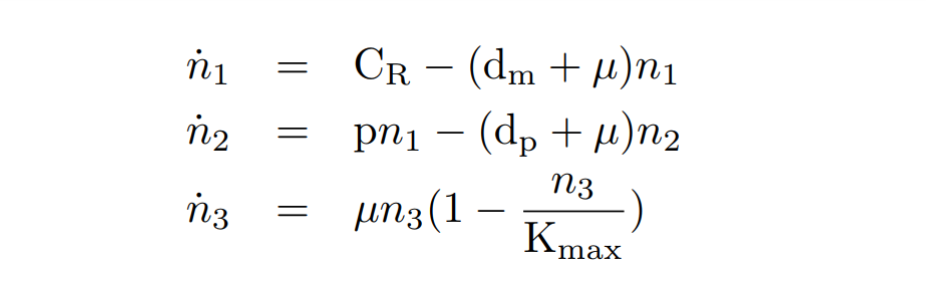
Constitutive expression model. Model equations.
After this, a series of quasi-steady state approximations [2] have been made. We have established that mRNA is generated at a constant CR constitutive transcription rate. In addition, the copy number of plasmids cn is kept as a constant. We consider that other species such as RNAP polymerases and ribosomes are kept constant as well.
The computational simulation of this ODE model uses two MATLAB files: the mc_simple.m function, which describes the system of differential equations, and the script model_const_simple.m where the parameters are defined and the model is solved by the ode45 MATLAB function. The simulation results are shown in the following Figure.
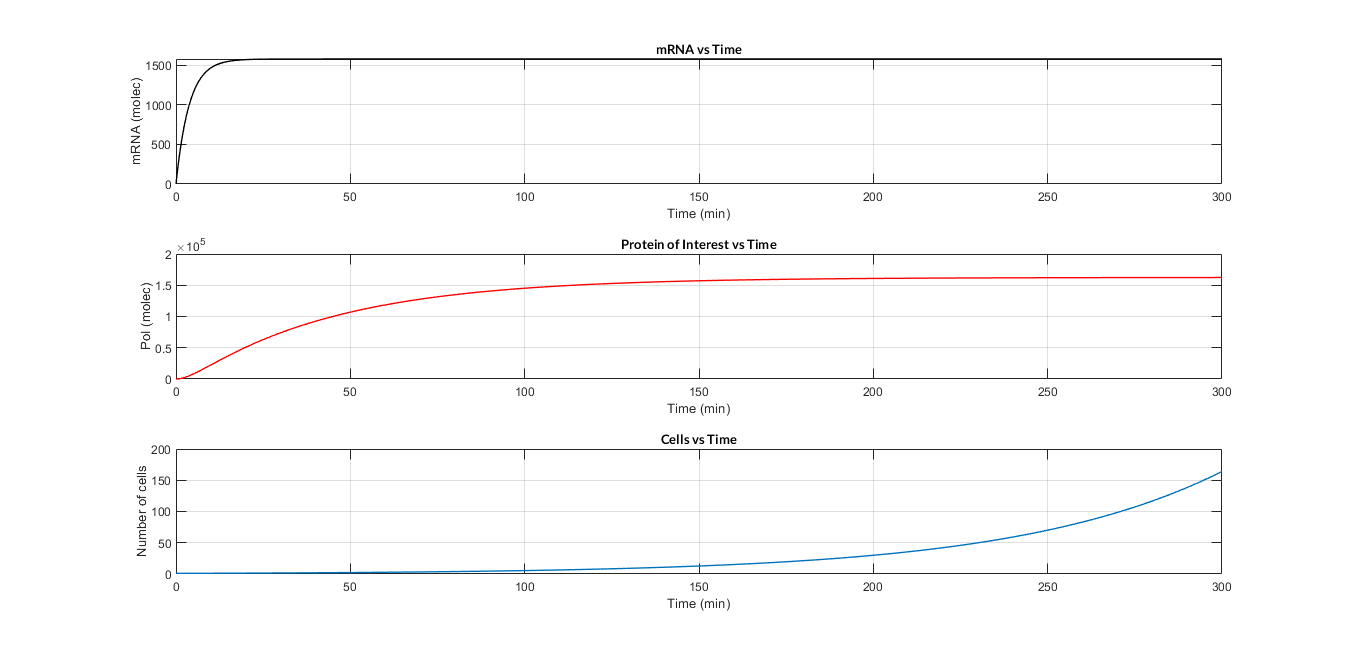
Constitutive expression model. Model predictions using parameter values from literature.
In the the temporal evolution of the mRNA and the protein PoI we can distinguish two phases: the transient phase and the stationary phase. If we perform different simulations varying some parameters of the model, we will observe how the equilibrium point of the stationary phase varies. MATLAB script mc_sim_analysis.m repeatedly simulates the model by changing the CR and p parameters. The following Figure shows how an increase of both parameteres implies a greater expression of the protein PoI.
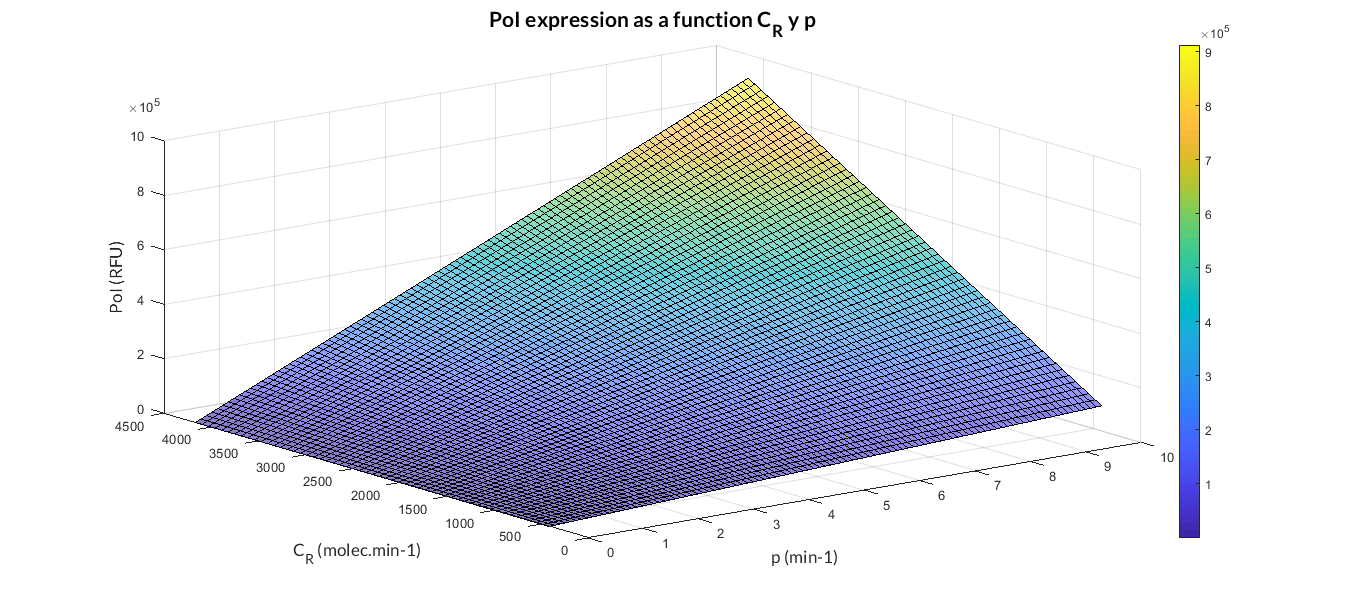
Constitutive expression model analysis. The graph represents de PoI stationary value as function of CR and p ratios.
At this point anyone could ask us: Which are the advantages of a constitutive expression model like this? Why is a model like this really useful to us? Faced with these questions, the Printeria Modeling team has looked for the answers in the great characteristics that the model offers us.
A simple, easy-to-understand model that clearly explains the processes of cellular transcription and translation.
It is valid for any Printeria construction that has a constitutive expression promoter. The variation between different constructions occurs in the parameters values, not in the model equations!
It has few parameters, with a clear physical meaning, and easily optimizable.
As a compact model, simulations and optimizations are performed at high speed.
Experiments & Optimization
The simple model of constitutive expression is a model that characterizes a large number of Printeria Transcriptional Units (TU), specifically, all those constructions whose promoter is constitutive. We know that all these TU follow the same model, but each one has different parameters, and therefore different experimental values of fluorescence and absorbance. Faced with this situation, the Printeria Lab and Modeling teams have designed some experiments, in which we have applied the multi-objective parameter optimization, and thus check whether the designed constitutive expression model responds to experimental reality.
We have designed two experiments following the same experimental protocol to assemble different Printeria TUs with the same promoter, CD (sfGFP reporter protein) and transcriptional terminator, but with different RBSs. Once a TU is made, we estimated the model parameters and particularly the RBS of every TU using the multiobjective optimization protocol.
Printeria RBS:
Strong expression: BBa_K2656009.
Medium expression: BBa_K2656011.
weak expression: BBa_K2656010.
Very weak expression: BBa_K2656008, BBa_K2656012.
Experiment parameters |
Description |
|---|---|
Time |
06:00:00 (HH:MM:SS). Measurement interval: 05:00 (MM:SS) |
Number of samples |
8 samples for each TU colony |
Number of medium samples |
8 samples of M9 medium |
Temperature |
37 ºC |
Shake |
Double Orbital. Continuously |
Absorbance. Optical Density (OD) measure |
Wavelenght at 600 nm emission |
Excitacion wavelength |
Wavelenght at 485 nm |
Emission wavelength |
Wavelenght at 528 nm |
Gain (G) |
60 |
Biotek Cytation 3 experimental parameters.
Optimization specifications |
Description |
|---|---|
Parameters |
Constitutive transcription rate CR: fixed Translation rate p: to optimize PoI degradation rate dp: to optimize mRNA degradation rate dm: fixed Dilution rate μ: to optimize Maximum growth capacity Kmax: experimental value |
Objetives to optimize |
For each TU, we set 2 objetives: FOD (Fluorescence per cell) and OD (Absorbance). In each experiment we measured 3 TU, so we are optimizing 6 objectives per experiment |
Parameter ranges |
Translation rate p: [0.001 - 6] min-1 PoI degradation rate dp: [0.0058 - 0.0087] min-1 Dilution rate μ: [0.0058 - 0.035] min-1 |
MATLAB files |
spMODEparam.m: it defines the parameters to be optimized, their value ranges, number of objectives, the cost function, the identification and validation experimental data and other spMODE algorithm parameters. When the script is executed, a spMODEDat structure variable is defined. This structure contains all the standardized optimization information that the spMODE algorithm will need for its execution.
spMODE.m: it contains the Multi-objective Differential Evolution Algorithm with Spherical Pruning, which optimizes parameters for our experimental results (to execute spMODE.m file we need also SphPruning.m file). CostFunction_RBS_RMS_2n.m: it simulates the model with different vector parameters, and calculates the Root Mean Square Error with the identification dataset. Then, it returns the error for each objective and parameter vector. levelDiagram.m: plots Pareto front and Pareto set that gives us back the algorithm. execute_RBS_2n.m: this script launches the optimization by executing spMODEparam.m, spMODEm algorithm and levelDiagram.m. Then, allows the user to enter the best parameters, and plots validation experimental data and simulation results in the same graph. |
Optimization specifications for the experiment.
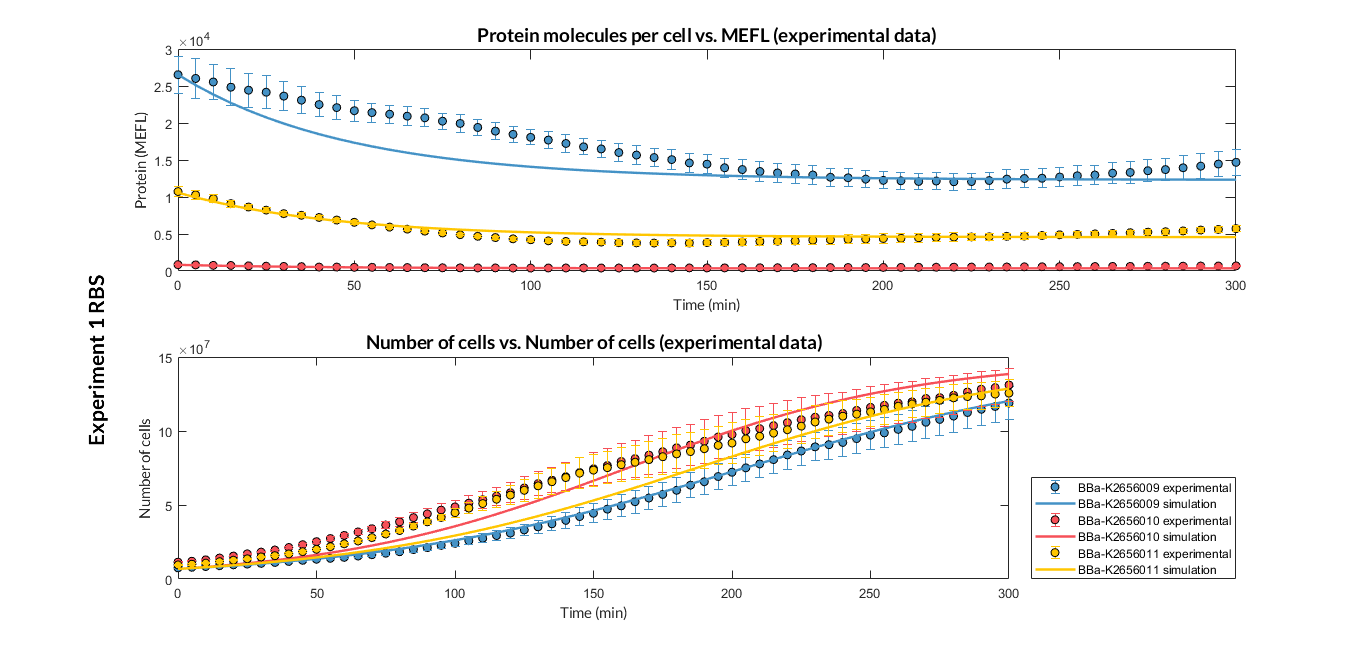
Experiment 1 changing RBS. Experimental and optimized simulated model data of strong, medium and weak protein expression RBS
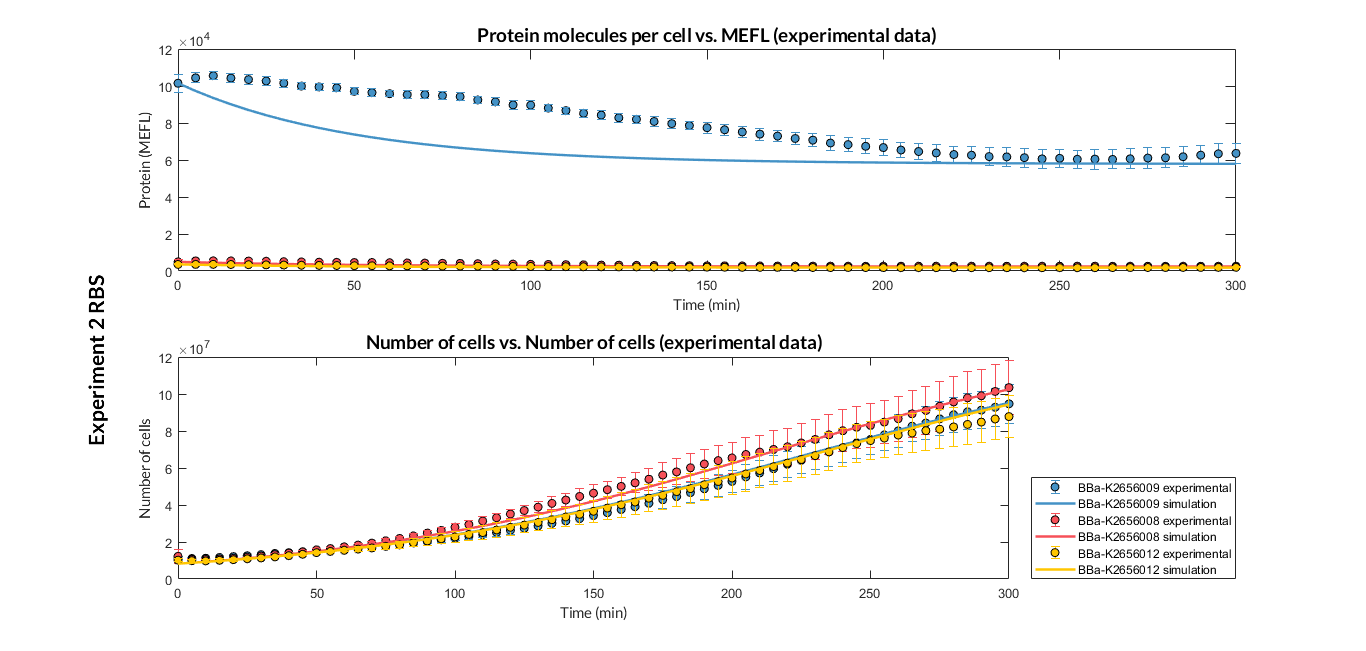
Experiment 2 changing RBS. Experimental and optimized simulated model data of strong and very weak protein expression RBS
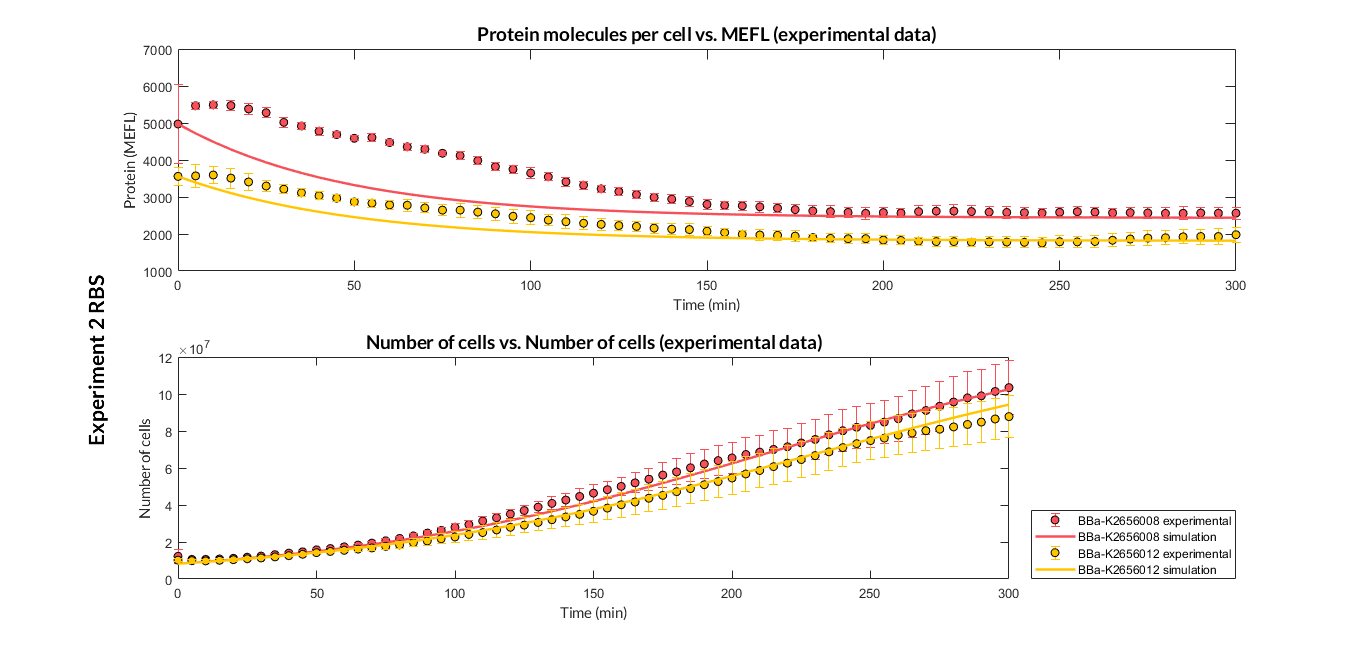
Experiment 2 changing RBS. Experimental and optimized simulated model data of very weak protein expression RBS
The results above were obtained after an optimization and decision-making process, where one set of the model parameters were selected to simulate the ODE model of every TU. These simulations were compared with the experimental data showing good agreement. The optimized set of model parameters are summarized in the following table.
Optimized parameters |
Values |
|---|---|
Translation rate p |
Experiment 1:
Experiment 2:
|
PoI degradation rate dp |
Experiment 1: dp = 0.0058 min-1 Experiment 2: dp = 0.00818 min-1 |
Dilution rate μ |
Experiment 1:
Experiment 2:
|
List of optimized parameters for RBS experiment.
In addition, the Printeria Modeling team has also calculated the relative strength between the different RBS, taking BBa_K2656009 strong RBS as a reference. The relative strength is the quotient between the values of the protein at the equilibrium point and the reference. The characterization of the RBS parts by their relative strength is shown below.
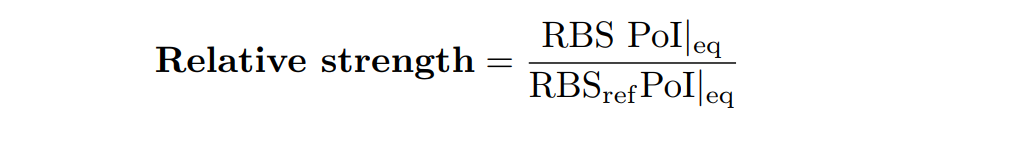
Original BioBrick RBS part |
Printeria RBS part |
Relative strength |
p parameter ratio (pRBS/pref) |
|---|---|---|---|
BBa_B0030 (Reference part) |
BBa_K2656009 (Reference part) |
1 |
1 |
0.371 |
0.398 |
||
0.045 |
0.048 |
||
0.042 |
0.044 |
||
0.031 |
0.031 |
Relative strength between different RBS parts.
We have designed two experiments following the same experimental protocol to assemble different Printeria TUs with the same RBS, CD (GFP reporter protein) and transcriptional terminator, but with different promoters. Then, following the optimization protocol we have obtained the model parameters and particularly the promoter values.
Printeria promoters:
Strong promoters: BBa_K2656005
Medium promoters: BBa_K2656007
Weak promoters: BBa_K2656004
Experiment parameters |
Description |
|---|---|
Time |
06:00:00 (HH:MM:SS). Measurement interval: 05:00 (MM:SS) |
Number of samples |
8 samples for each TU colony |
Number of medium samples |
8 samples of M9 medium |
Temperature |
37 ºC |
Shake |
Double Orbital. Continuously |
Absorbance. Optical Density (OD) measure |
Wavelenght at 600 nm emission |
Excitacion wavelength |
Wavelenght at 485 nm |
Emission wavelength |
Wavelenght at 528 nm |
Gain (G) |
60 |
Biotek Cytation 3 experimental parameters.
Optimization specifications |
Description |
|---|---|
Parameters |
Constitutive transcription rate CR: to optimize Translation rate p: fixed PoI degradation rate dp: to optimize mRNA degradation rate dm: fixed Dilution rate μ: to optimize Maximum growth capacity Kmax: experimental value |
Objetives to optimize |
For each TU, we set 2 objetives: FOD (Fluorescence) and OD (Absorbance). In each experiment we have measured 3 TU, so we are optimizing 6 objectives per experiment |
Parameter ranges |
Constitutive transcription rate CR: 500 x [0.001 - 5] min-1 PoI degradation rate dp: [0.0058 - 0.0087] min-1 Dilution rate μ: [0.0058 - 0.035] min-1 |
MATLAB files |
spMODEparam.m: it defines the parameters to be optimized, their value ranges, number of objectives, the cost function, the identification and validation experimental data and other spMODE algorithm parameters. When the script is executed, a spMODEDat structure variable is defined. This structure contains all the standardized optimization information that the spMODE algorithm will need for its execution. In this experiment, we have used the spMODEparam_exp6GFP.m MATLAB script. spMODE.m: it contains the Multi-objective Differential Evolution Algorithm with Spherical Pruning, which optimizes parameters for our experimental results (to execute spMODE.m file we need also SphPruning.m file). CostFunction_Prom_RMS_2n.m: it simulates the model with different vector parameters, and calculates the Root Mean Square Error with the identification dataset. Then, it returns the error for each objective and parameter vector. levelDiagram.m: plots Pareto front and Pareto set that gives us back the algorithm. execute_Prom_2n.m: this script launches the optimization by executing spMODEparam.m, spMODEm algorithm and levelDiagram.m. Then, allows the user to enter the best parameters, and plots validation experimental data and simulation results in the same graph. |
Optimization specifications for the experiment.
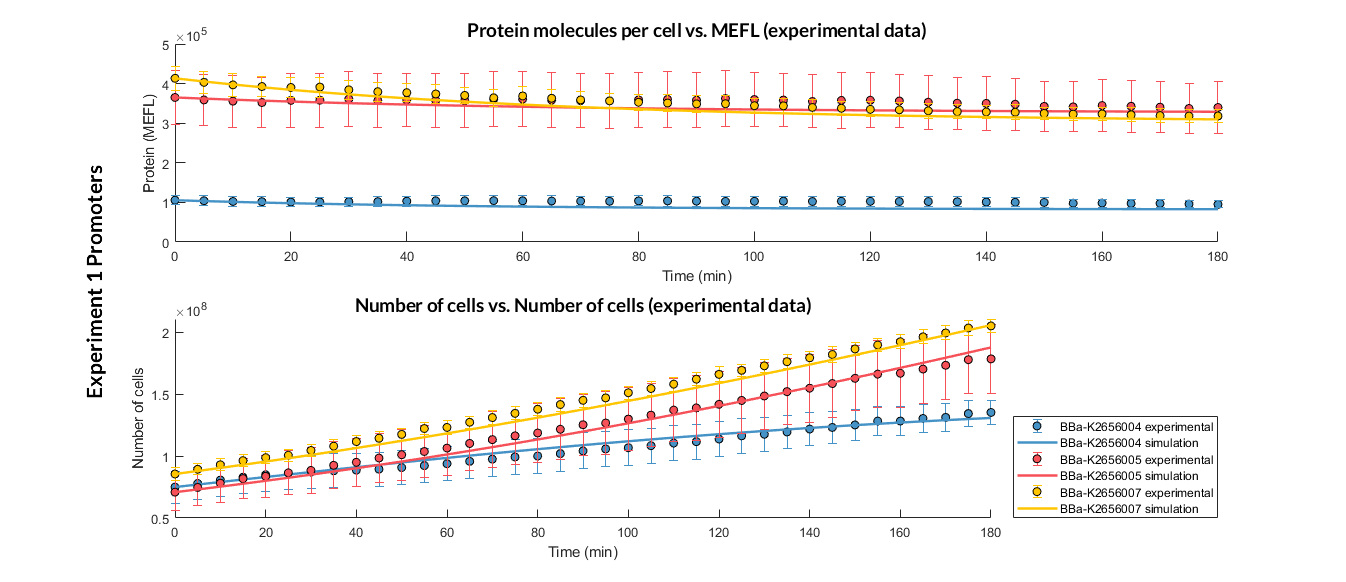
Experiment 1 changing promoters. Experimental and optimized simulated model data of strong, medium and weak promoters.
The results above were obtained after an optimization and decision-making process, where one set of the model parameters were selected to simulate the ODE model of every TU. These simulations were compared with the experimental data showing good agreement.
Optimized parameters |
Values |
|---|---|
Constitutive transcription rate CR |
|
PoI degradation rate dp |
dp = 0.008492 min-1 |
Dilution rate μ |
|
List of optimized parameters for promoters experiment.
In addition, the Printeria Modeling team has also calculated the relative strength between the different promoters, taking BBa_K2656005 strong promoter as a reference. The characterization of the promoter parts by their relative strength is shown below.
Original BioBrick RBS part |
Printeria RBS part |
Relative strength |
p parameter ratio (pProm/pref) |
|---|---|---|---|
BBa_J23102 (Reference part) |
BBa_K2656005 (Reference part) |
1 |
1 |
0.9367 |
0.9013 |
||
0.2603 |
0.3172 |
Relative strength between different promoter parts.
In the following experiment we want to compare the degradation rate of different protein reporters in two Printeria TUs with identical promoters, RBS and transcriptional terminators. An LVA degradation tag has been added to one of the protein sequences. This tag causes an increase of protease activity, so it means a faster degradation rate of the reporter protein. A priori, the degradation rate in the TU with the LVA tag will be higher.
With these experiments, the team aims:
To analyze the effect of the protein degradation rate variation on our constitutive expression model, and determine if the model fits the experimental results of the reporter proteins with LVA degradation tag.
To characterize the YFP reporter protein with LVA tag as a new iGEM part and as Improve project .
The experiments and optimization process performed for each reporter protein are described below. We have followed the experimental protocol and multi-objective optimization protocol.
Experiment parameters |
Description |
|---|---|
Time |
06:00:00 (HH:MM:SS). Measurement interval: 05:00 (MM:SS) |
Number of samples |
8 samples for each TU colony |
Number of medium samples |
8 samples of M9 medium |
Temperature |
37 ºC |
Shake |
Double Orbital. Continuously |
Absorbance. Optical Density (OD) measure |
Wavelenght at 600 nm emission |
Excitacion wavelength |
Wavelenght at 500 nm |
Emission wavelength |
Wavelenght at 540 nm |
Gain (G) |
60 |
Biotek Cytation 3 experimental parameters.
Optimization specifications |
Description |
|---|---|
Parameters |
Constitutive transcription rate CR: fixed Translation rate p: to optimize PoI degradation rate dp: to optimize mRNA degradation rate dm: fixed Dilution rate μ: to optimize Maximum growth capacity Kmax: experimental value |
Objetives to optimize |
For each TU, we set 2 objetives: FOD (Fluorescence) and OD (Absorbance). In this experiment we have measured 2 TU, so we are optimizing 4 objectives per experiment |
Parameter ranges |
Constitutive transcription rate CR: [0.01 - 2] min-1 PoI degradation rate dp: [0.0058 - 0.018] min-1 Dilution rate μ: [0.0058 - 0.035] min-1 |
MATLAB files |
spMODEparam.m: it defines the parameters to be optimized, their value ranges, number of objectives, the cost function, the identification and validation experimental data and other spMODE algorithm parameters. When the script is executed, a spMODEDat structure variable is defined. This structure contains all the standardized optimization information that the spMODE algorithm will need for its execution. In this experiment, we have used spMODEparam_exp1YFP.m spMODE.m: it contains the Multi-objective Differential Evolution Algorithm with Spherical Pruning, which optimizes parameters for our experimental results (to execute spMODE.m file we need also SphPruning.m file). CostFunction_improve_RMS_2n.m: it simulates the model with different vector parameters, and calculates the Root Mean Square Error with the identification dataset. Then, it returns the error for each objective and parameter vector. levelDiagram.m: plots Pareto front and Pareto set that gives us back the algorithm. execute_improve_2n.m: this script launches the optimization by executing spMODEparam.m, spMODEm algorithm and levelDiagram.m. Then, allows the user to enter the best parameters, and plots validation experimental data and simulation results in the same graph. |
Optimization specifications for the experiment.
After the multiobjective optimization process, we selected one of the solution for the model parameters and then we compared the model simulations with the experimental data. For both TUs, the simulation results match with the experimental ones.
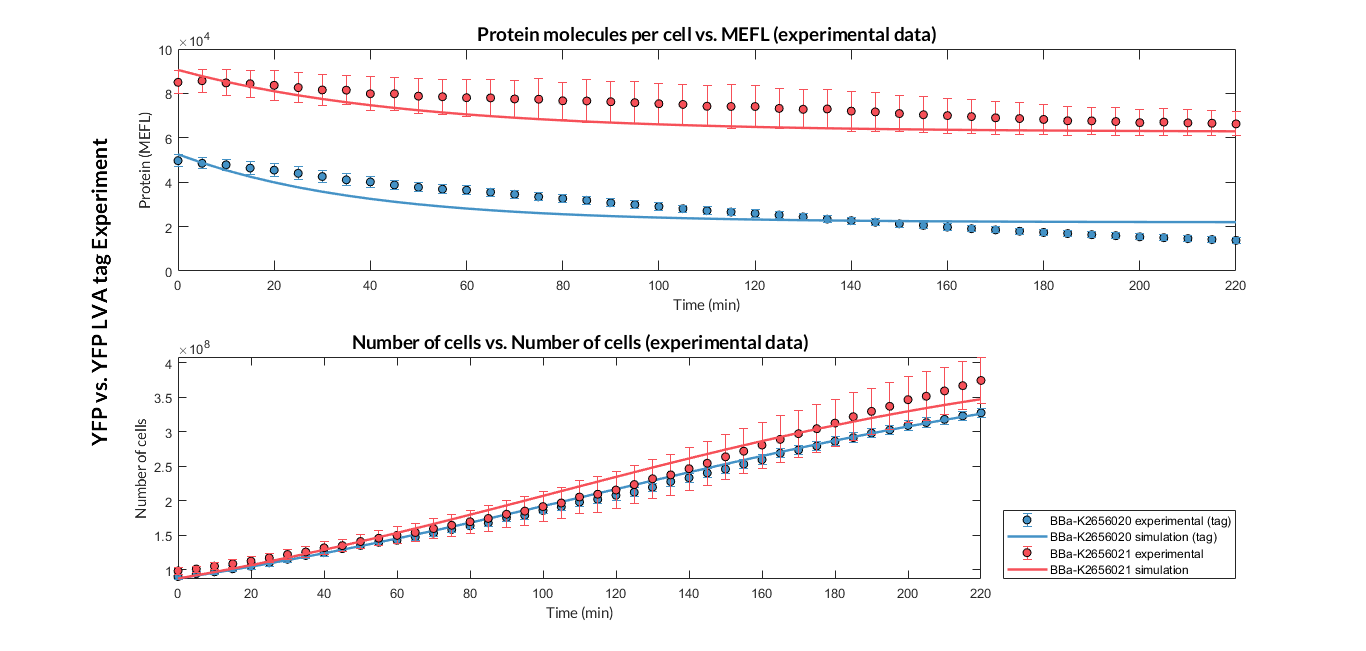
Experiment YFP vs. YFP tag. Experimental data and optimized model of the YFP and YFP tag proteins
Optimized parameters |
Values |
|---|---|
Translation rate p |
| PoI degradation rate dp |
|
Dilution rate μ |
|
List of optimized parameters.
At this point, it is easy to see that the degradation rate is significantly higher in the reporter protein with the degradation LVA tag than the YFP protein. Computing the ratio of the degradation rates for both YFP proteins, we observe that the value of the protein with the LVA tag is about twice the value of the protein without LVA tag.
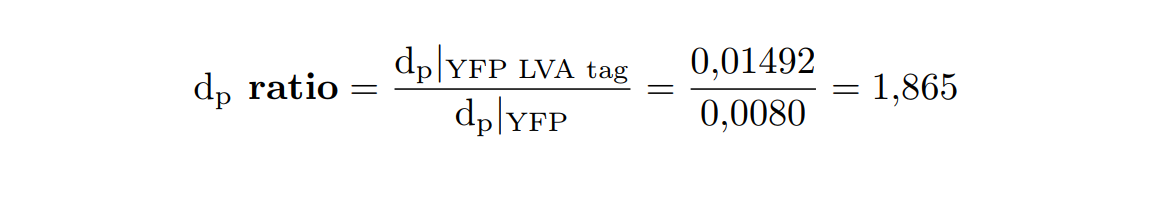
Inducible expression models
Inducible expression models are those where protein expression depends on one or more inducing molecules. They are called activators or repressors. The concentration of these biochemical species determines if the transcription is activated or repressed, respectively.
Our Printeria device gives us the possibility to create some inducible genetic constructs:
PBAD/araC inducible model
The inducible promoter PBAD/araC [5] is a promoter whose expression depends on two inducing complexes: the L-arabinose (activator) and the araC (repressor). The dimeric protein araC binds DNA to compound a DNA loop and thus prevents the binding between DNA and RNA polymerase. However, when two arabinose molecules bind the araC dimer, the DNA loop is broken and the binding between the RNA polymerase and the promoter region is possible.
We have proposed an ODE model describing the PBAD/araC mechanism. This theoretical model has been included in the Simulation Tool, so Printeria is able to predict the behavior of the PBAD/araC inducible promoter circuits.
Model design
We propose the following scheme that describe the biochemical reactions of the PBAD/araC system. We have assumed a very high concentration of araC inside the cell because the gene encoding for the araC protein is found in the cell genome of some strains (e.g. in DH5α strains).
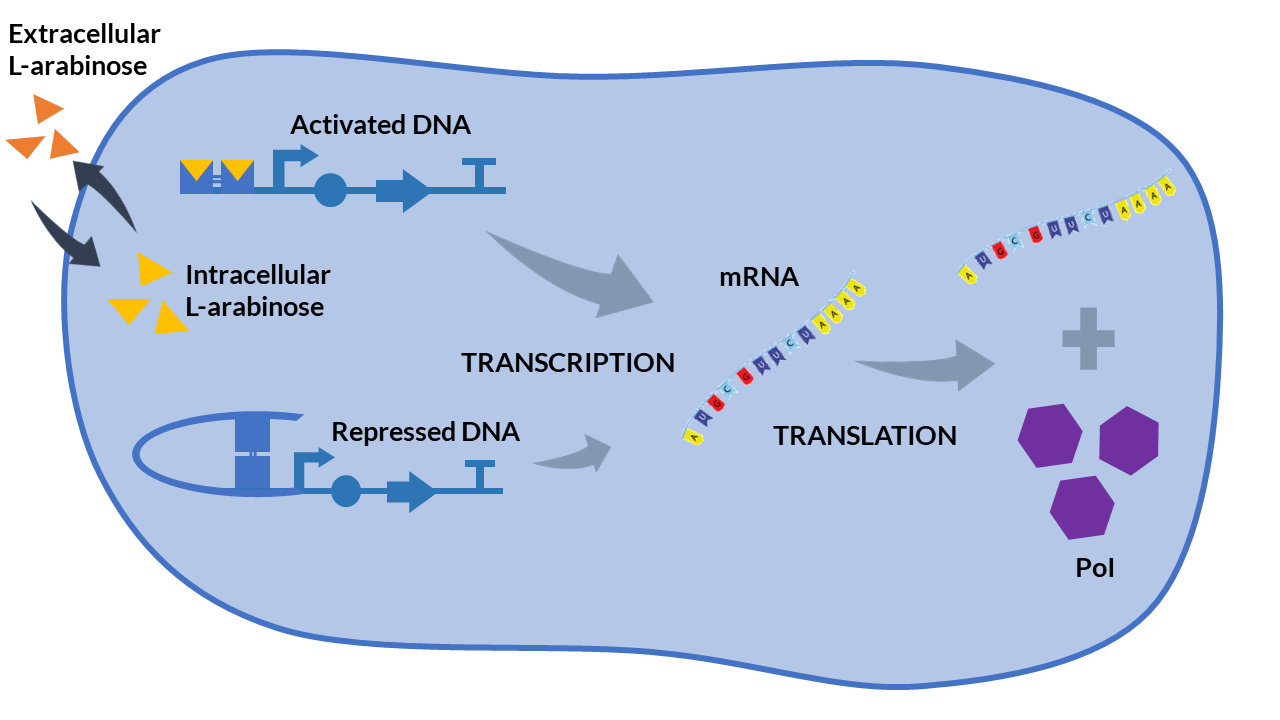
PBAD/araC inducible model. Cell schema.
From the cell schema we infer the following biochemical reactions:
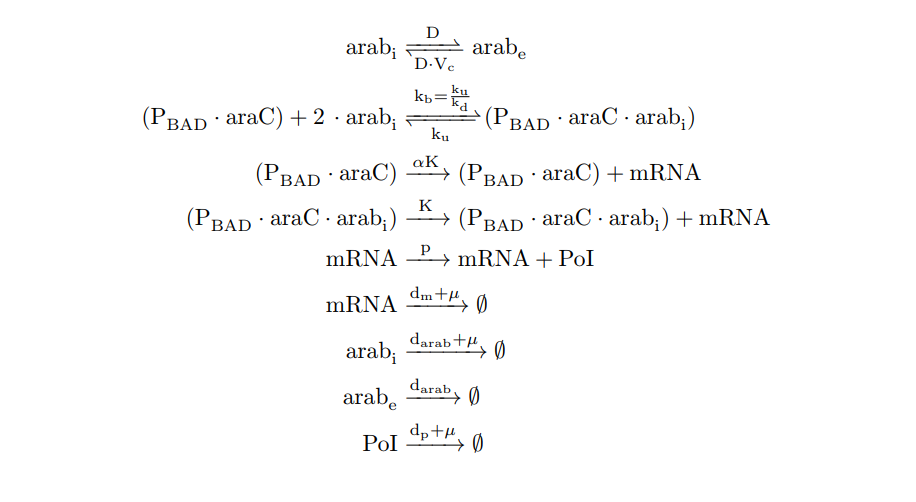
PBAD/araC inducible model. Biochemical reations.
Parameter |
Description |
Units |
Value |
|---|---|---|---|
D |
Diffusion coefficient | min-1 |
2 [2] |
Vc |
Cell volume(1.1x10-9 μL)/External volume(1x10-3 μL) | adimensional |
1.1x10-6 [2] |
ku |
Dissociation rate of (PBAD.araC.arabi) complex | min-1 |
10 [10] |
kd |
Dissociation constant of (PBAD.araC.arabi) complex | molec2 |
|
kb |
Association rate of (PBAD.araC.arabi) complex. ku/kd | molec-2min-1 |
0.1 (Estimated) |
K |
Transcription rate is the product of transcription rate per plasmid Kt and the mean number of plasmids in cell cn . In our case, we are using the pMBI replication origin, so cn ∼ 500, and K = Kt·cn. |
min-1 |
|
α |
(PBAD.araC) basal activity constant | adimensional |
0.01 (Estimated) |
p |
mRNA translation rate |
min-1 |
2.38 [2] |
darab |
L-arabinose degradation rate. We assume a very slow degradation. |
min-1 |
∼10-6 |
dm |
mRNA degradation rate |
min-1 |
0.247 [7] |
dp |
PoI degradation rate |
min-1 |
0.0063 [5] |
μ |
Dilution rate |
min-1 |
0.017 [5] |
Kmax |
Maximum growth capacity |
cells |
1.6·108 [5] |
PBAD/araC inducible model. Model parameters.
We apply the Law of Mass Action kynetics (LMA) to obtain the equivalent ODE model. Considerin the same previous assumptions for the constitutive models, and also the fact the the plasmid copy number cn is kept as a constant, we can obtain a reduced oreder model. Thus, we get a model of six differential equations and one algebraic equation as below.
Variable |
Biochemical species |
Units |
|---|---|---|
n1 |
(PBAD.araC.arab) complex |
Molecules |
n2 |
Extracellular L-arabinose |
Molecules |
n3 |
Intracellular L-arabinose |
Molecules |
n4 |
mRNA |
Molecules |
n5 |
PoI |
Molecules |
n6 |
Number of cells |
Cells |
PBAD/araC inducible model. Biochemical species.
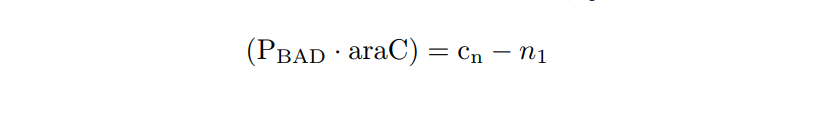
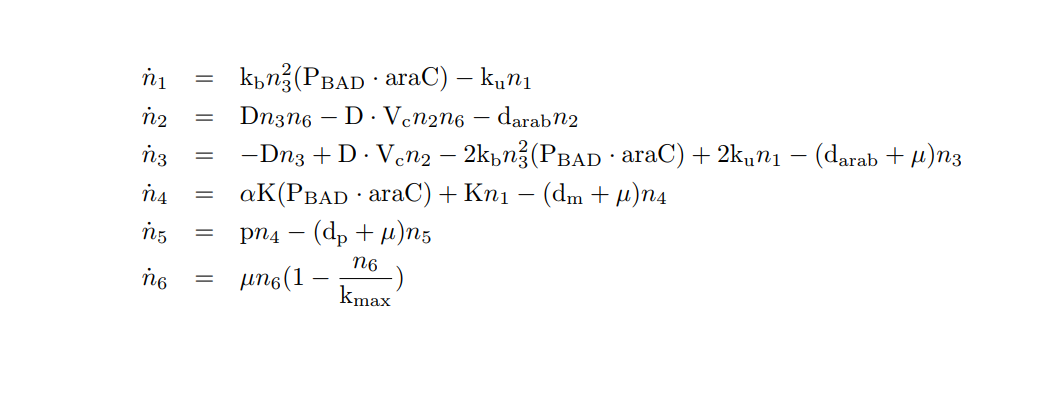
PBAD/araC inducible model. Model equations.
Now we have two MATLAB files: the mi_araC_simplest.m function, which describes the ODE model, and the script model_inducible_simplest.m where the parameters are defined. The model was simulated by using the ode23t MATLAB function. The simulation results are shown below.
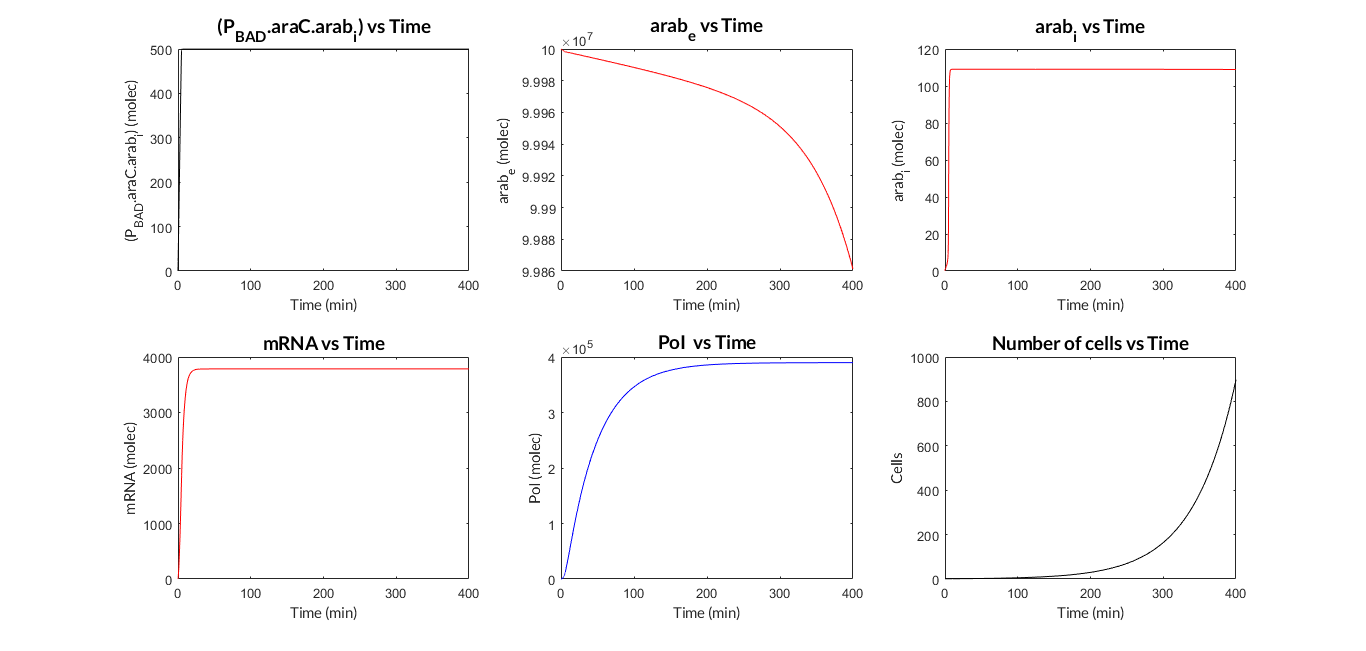
PBAD/araC inducible model. Model predictions using parameter values from literature.
Once the PBAD/araC model was validated, we simulated the model varying the some of its parameters (MATLAB script analysis_mi_araC_simplest.m). In this case, we have modified the K transcription rate and the p translation rate.
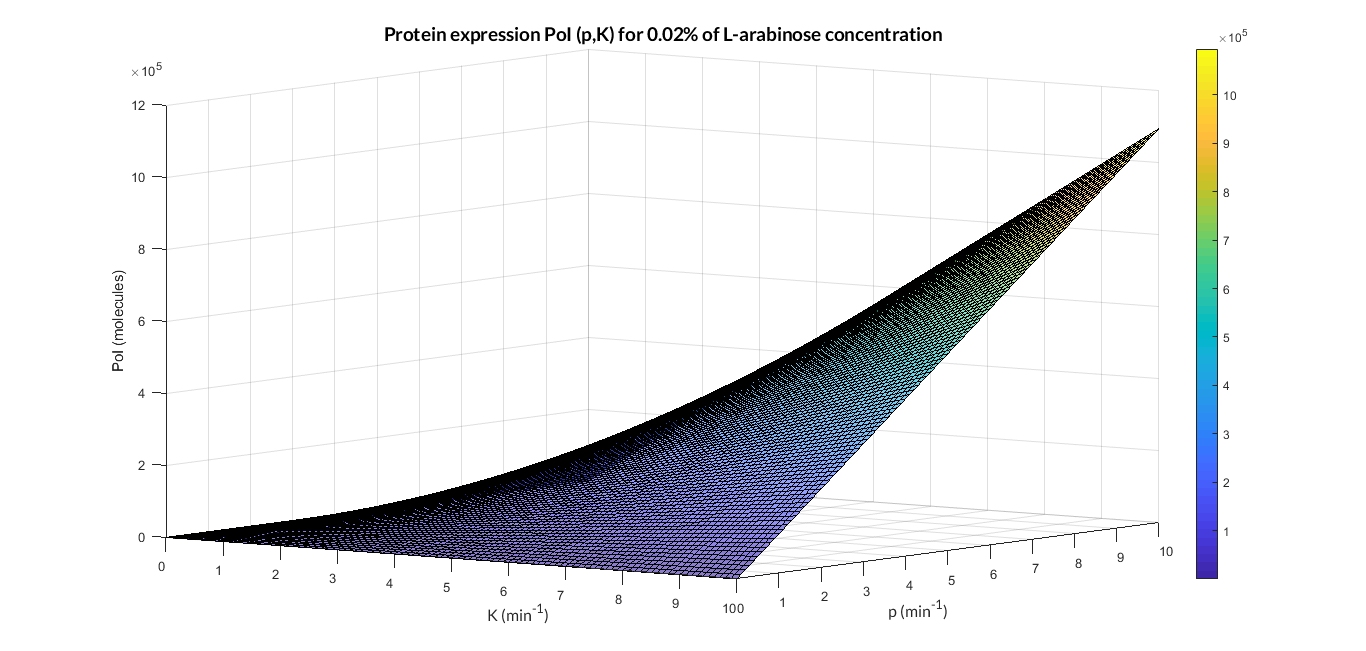
PBAD/araC inducible model analysis. The graph represents de PoI stationary value as function of p and K ratios.
As we can see in the 3D graph, the protein expression of PoI exponentially increases when the translation rate p and transcription rate K become higher.
But we can also change the initial concentration of L-arabinose in the PBAD/araC model as shown in the figure below. The simulations for several p and arab0 parameters were ran using the analysis_mi_araC_simplest_arab.m MATLAB script.
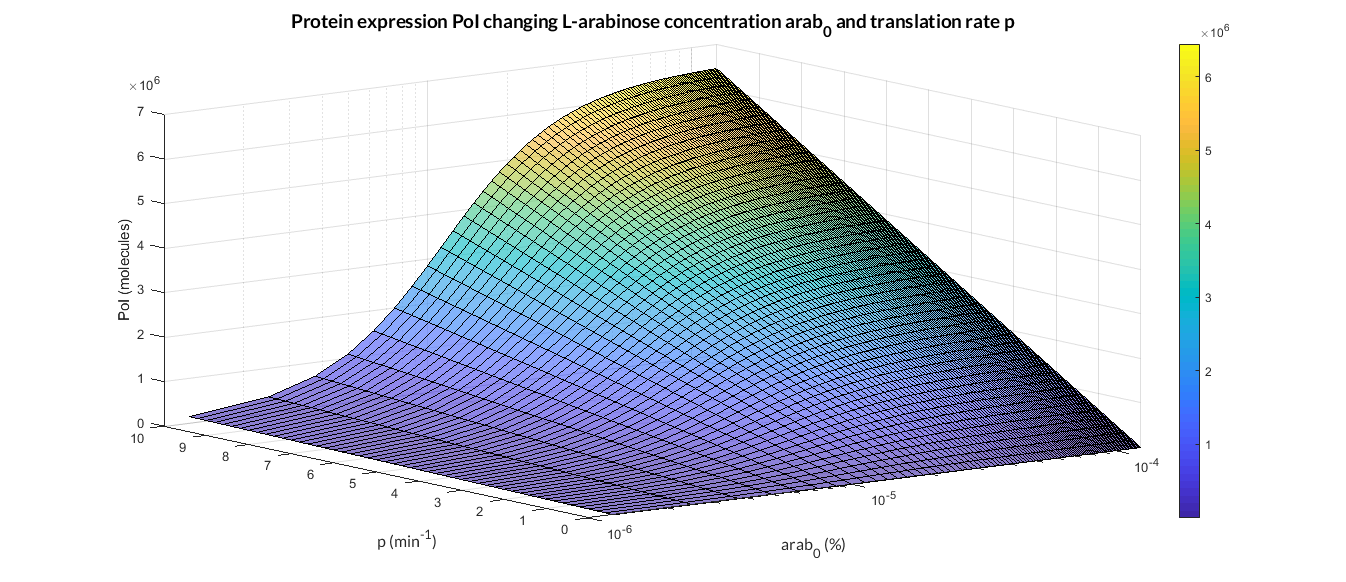
PBAD/araC inducible model analysis. The graph represents de PoI stationary value as function of p ratio and L-arabinose concentration (arab0).
AHL-LuxR inducible model
The AHL-LuxR genetic circuit [2] is a more complex genetic circuit than the models presented so far. It couples two functional subsystems: i) quorum sensing interconnecting cell population with the external inducer AHL, and ii) an intracellular loop to regulate expression of the protein of interest.
The first subsystem implements a cell-to-cell communication mechanism via quorum sensing. It is based on the exchange of the small signaling autoinducer molecule N-acyl-L-homoserine lactone (AHL) to induce population cell consensus. AHL molecules passively diffuses across the cellular membrane from inside the cell to the external environment, and viceversa, following Fick’s Law.
The second subsystem introduces an intracellular loop to control expression of the protein of interest, in this case GFP. First, LuxR protein is expressed by luxR under the constitutive promoter Pc. Then, LuxR and AHL bind forming the heterodimer (LuxR.AHL), which subsequently dimerizes as the heterotetramer transcription factor (LuxR.AHL)2. The dimer represses protein expression when it is attached to the promoter Plux.
Model design
We propose the following biochemical reactions based on the Boada et al.(2017) model [2].
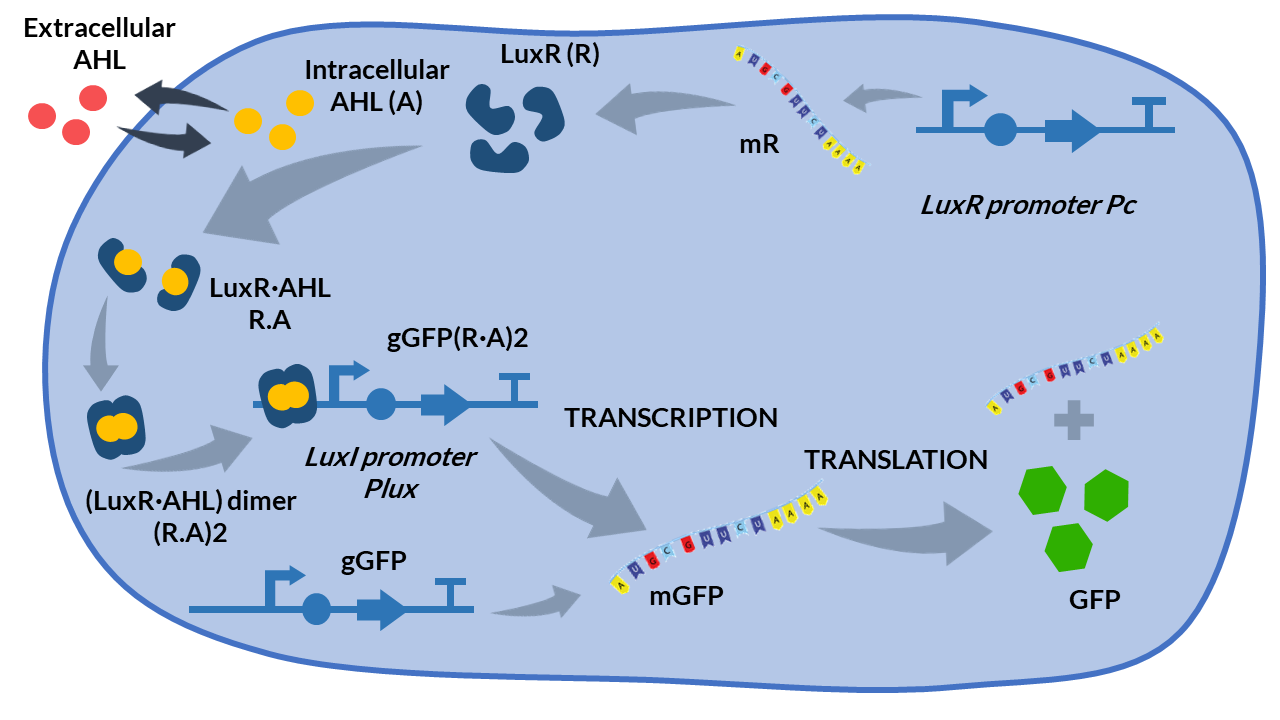
AHL-LuxR inducible model. Cell schema.
From the schema, we can obtain the following biochemical reactions:

AHL-LuxR inducible model. Biochemical reactions.
Parameter |
Description |
Units |
Value |
|---|---|---|---|
CR |
Constitutive transcription rate is the transcription rate KR times the mean plasmid copy number in cell cn. In our case, we are using the pACYC replication origin, so cn ∼ 10, and CR = KR·cn |
molecules.min-1 |
7.9 |
keG |
gGFP transcription rate |
molecules.min-1 |
17.5 |
α |
PluxR promoter basal activity | adimensional |
0.1 (Estimated) |
pR |
mR translation rate |
min-1 |
10 |
pG |
mGFP translation rate |
min-1 |
3.09 |
kA |
Synthesis rate of AHL by LuxI |
min-1 |
0.04 |
k-1 |
Dissociation rate of (R·A) | min-1 |
10 |
k-2 |
Dissociation rate of (R·A)2 | min-1 |
1 |
kd1 |
Dissociation constant of (R·A) | molecules |
100 |
kd2 |
Dissociation constant of (R·A)2 | molecules |
20 |
kdlux |
Dissociation constant of (R·A)2 to the PluxR promoter | molecules |
10 |
dG |
GFP degradation rate |
min-1 |
0.027 |
dR |
R degradation rate |
min-1 |
0.2 |
dA |
A degradation rate |
min-1 |
0.057 |
dAe |
A degradation rate in culture medium |
min-1 |
0.057 |
dRA |
(R·A) degradation rate |
min-1 |
0.156 |
dRA2 |
(R·A)2 degradation rate |
min-1 |
0.017 |
dmR |
mR degradation rate |
min-1 |
0.247 |
D |
Diffusion coefficient of AHL through the cell membrane | min-1 |
2 |
Vc |
Cell volume(1.1x10-9 μL)/External volume(1x10-3 μL) | adimensional |
1.1x10-6 |
N |
Number of cells | cells |
240 |
AHL-LuxR inducible model. Model parameters.
Applying the Law of Mass Action kynetics (LMA) and some quasi-static approximations as before, we can obtain the following ODE model of the AHL-LuxR inducible system.
Variable |
Biochemical species |
Units |
|---|---|---|
n1 |
GFP protein |
Molecules |
n2 |
LuxR protein |
Molecules |
n3 |
Dimer of (R.A)2 |
Molecules |
n4 |
AHL intracellular inducer |
Molecules |
n5 |
AHLext intracellular inducer |
Molecules |
n6 |
Monomer (R.A) |
Molecules |
AHL-LuxR inducible model. Biochemical species.
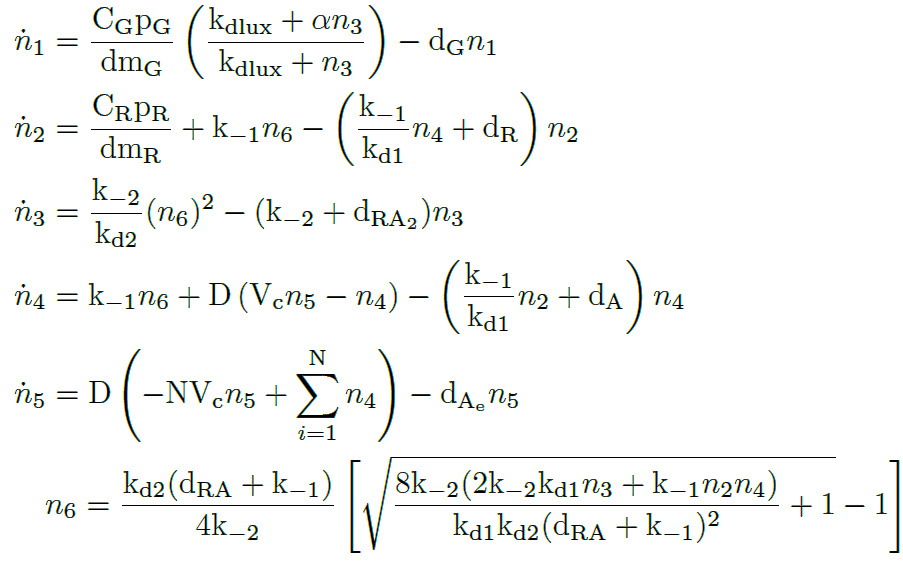
AHL-LuxR inducible model. Model equations.
As we can see, the model has five differential equations plus one algebraic equation. This model does not describe cell growth, but it considers a constant number of cells N. This is because the measurements were taken in a bioreactor that has one influx with medium similiar to another efflux which washes the cells away. Both fluxes are proportional to the dilution rate, so the cell density is kept constant.
We have programmed a MATLAB function called mi_lux.m for the ODE model, and also a MATLAB script called model_lux.m to define the parameters and simulate the model (ode15s MATLAB function).
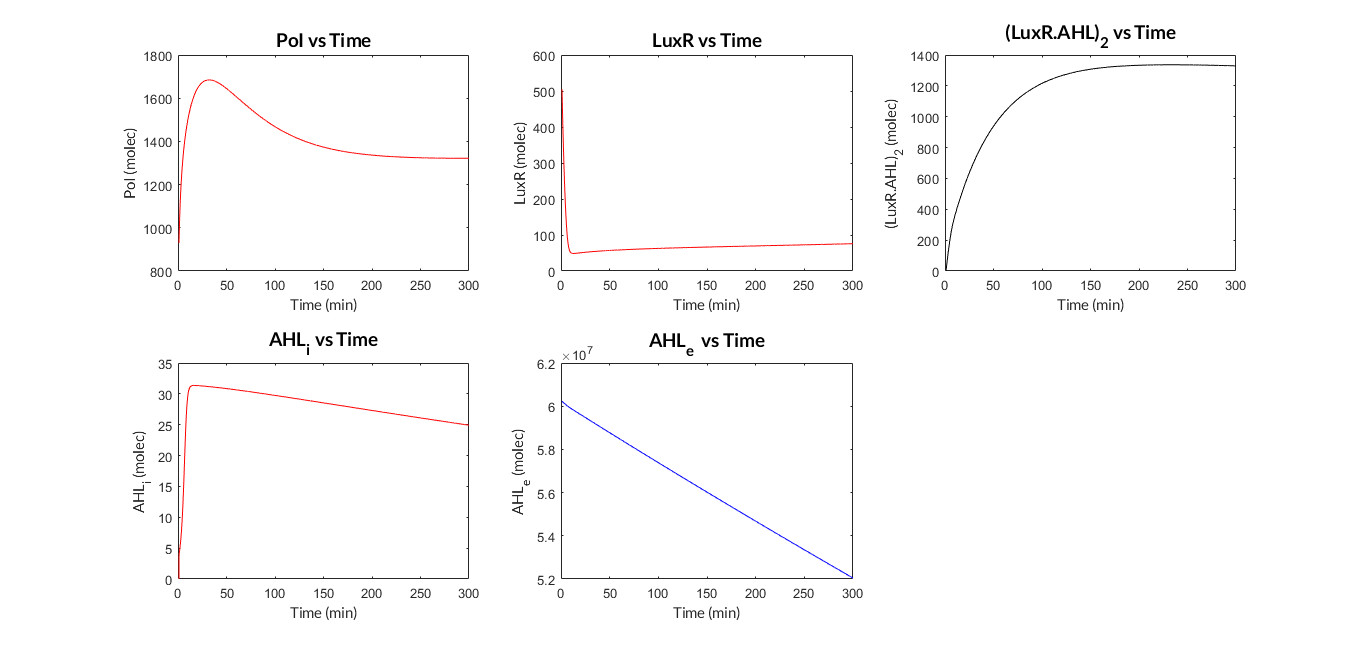
AHL-LuxR inducible model. Model predictions using parameter values from literature.
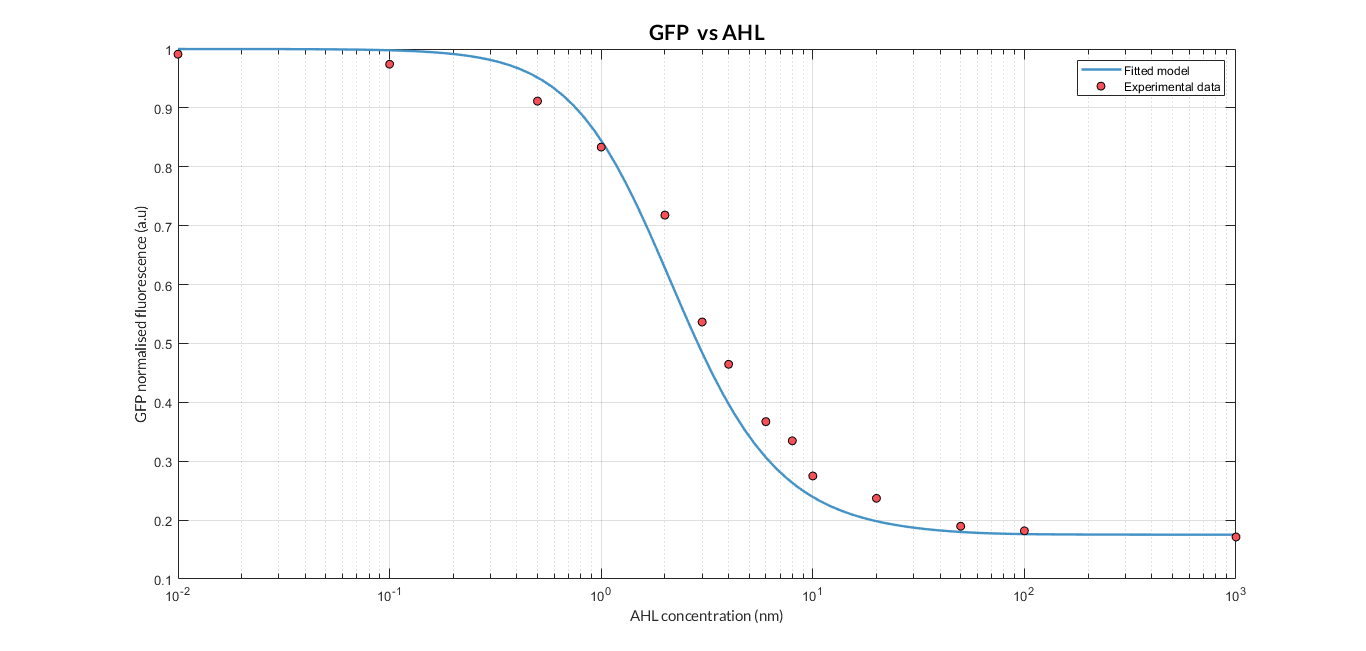
AHL-LuxR inducible model analysis. The graph shows the relation between AHL concentration and protein expression.
As we can see, the results show a clear dependence between the expression of the protein and the inducing AHL concentration. Comparing the experimental data (normalized for different AHL concentrations) with the simulated results, we can see that both closely match and this dynamics is the so-called Hill function.
Multi-objective parameter optimization
To what extent is our model valid? What values should the parameters take? To what extent do the theoretical results resemble the experimental ones? Is our model able to explain the behaviour of cells in reality?
One of the most important phases in the field of Printeria Modeling has been the validation of theoretical models with experimental data. In the Printeria team we wanted to confirm that the models designed are consistent with our experiments. However, we know that the parameters will not take a fixed value, but vary depending on the genetic construction with which we experiment. With this idea in mind, the need to apply an optimization process arises.
The multiobjective parameter optimization process [3] minimizes two or more design objectives that have a trade-off between them. They are cost functions that depend on some decision variables. In our case, these objectives are estimation errors between experimental data and the model predictions, whereas the decission variables are some of our model parameters. Using a mathematical algorithm to perform multiobjective optimization, we can find the optimal solutions for the model parameters also known as Pareto Front. The Pareto front has the optimal solutions that do not improve one objective without worsening the remaining objectives.
In multi-objective optimization, there is no single solution, but rather a set of them which form the Pareto front. For each of these solutions, we find a set of decision variables: the Pareto set [6]. In our case, the Pareto front solutions represent the RMS error between experimental data and model predictions, and the Pareto set has the sets of parameters associated to one Pareto front solution.
The Printeria Modeling team has established a protocol to obtain the optimal solutions of the model parameters for any experiment:
We define the objectives to be optimized. These will be the values of Fluorescence F/Unit of Absorbance OD or FOD, and the cellular growth (OD) of a Transcriptional Unit (TU). Therefore, if we have different n TU in an experiment, we will optimize 2n objectives.
We choose the parameters to optimize and establish the range of values they can take.
We select the identification and validation data. The identification data are those used in the optimization process. The validation data are used to compare the experiment with the simulated theoretical model and the optimized parameters.
We define the cost function, which specifies the error function to be minimized. It simulates the model for different parameter values, and calculates the error between the simulation data and the experimental identification data.
The mathematical optimization algorithm is executed. In our case we use the Multi-objective Differential Evolution Algorithm with Spherical Pruning. This algorithm uses the cost function to test different parameter values and thus search for optimal parameter values.
The Pareto set and Pareto front diagrams and the different solutions of our optimized parameters for the different objectives are obtained.
Decision Making is carried out by the designer. The optimal parameters are chosen for our 2n objectives.
The model is simulated with the optimized parameters and compared with the validation data.
Following this protocol for each experiment, we have determined the best parameters for our models that fully fit the experimental data.
Simulation Tool
One of the main challenges of Printeria has been to give the user a chance to really understand what our device is doing when it prints genetic circuits on bacteria. So we have also sought to provide as much information as possible about the Printeria product. And what better way than to give our user a quantitative, mathematical description of what happens in our cells?
In our project we believe that mathematical modeling can be a very powerful tool for transmitting knowledge, so the Printeria Software and Modeling teams have brought together the most outstanding mathematical models in a single Simulation Tool.
Our Simulation Tool has been conceived as a mathematical model simulation program that has been perfectly integrated into our Printeria Controller software. When our user wants to assemble a genetic construct and selects the parts, the Simulation Tool offers the possibility to experiment in silico and predict cell behavior before printing the bacteria. All this, just by pressing the Show model results button... and instantly!
But how does the Simulation Tool work?
The Printeria Modeling and Software teams have jointly designed a program developed in a single Python script (have a look at our simulate.py script). The program combines the functions of the main mathematical models of Printeria with the information of the Printeria kit stored in the Printeria database. In addition, as it is a single Python file, it is stored and run on the Raspberry Pi 3 server.
Now let's see what happens if the user has chosen the Printeria parts and presses the Simulate button...
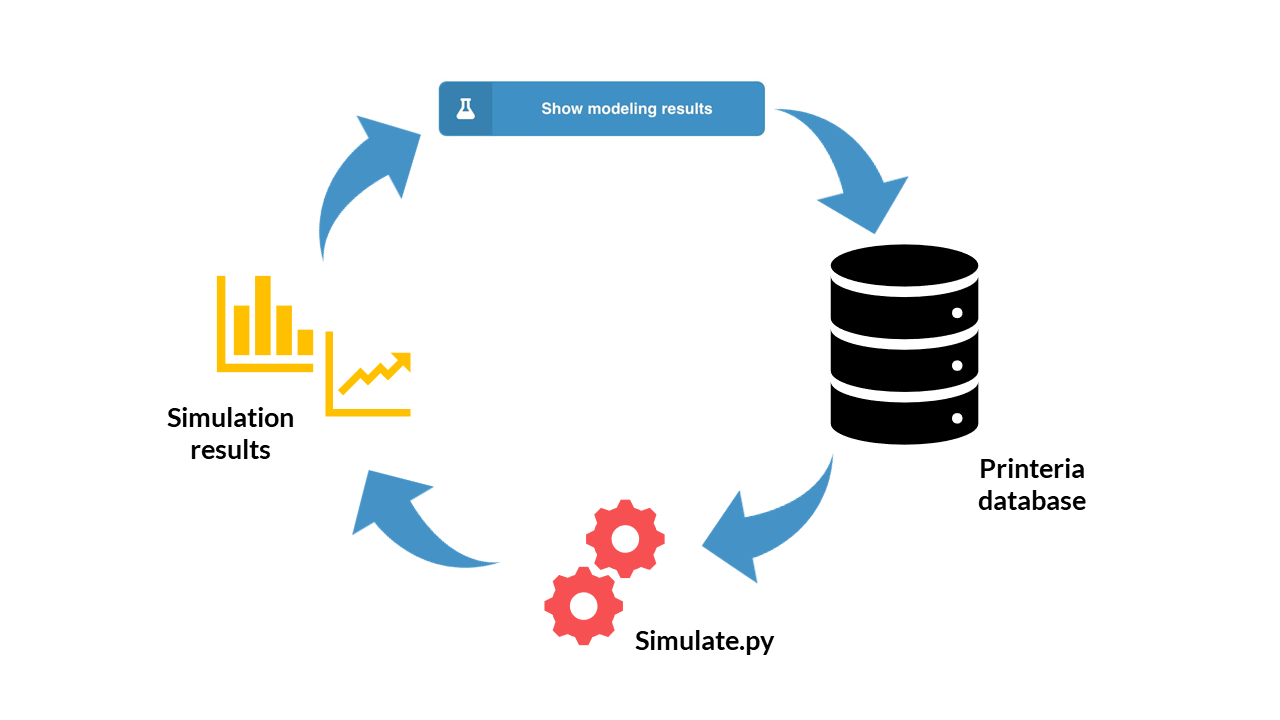
Simulation Tool working scheme.
The Printeria client connects to the Printeria database (MongoDB) where we store all the information of our Printeria kit.
The four parts of the genetic construction (promoter, RBS, CDS and transcriptional terminator) are extracted from the database thanks to their identifiers.
The type of model (constitutive or inducible expression) is identified from the type of promoter selected.
The model parameters of each construction part are extracted.
The initial conditions of the simulation and its duration are established.
The model is simulated using Python's odeint function
A temporary CSV file is generated in which the we store the results of the simulation in a certain format.
From the CSV file, the simulation results are represented graphically on the Printeria site. The user can view or download their results.
And what are the advantages of an application like our Simulation Tool?
User-friendly. It is very simple to operate for the user. Just select your Printeria parts, press a button... And that's it!
Integrated. All our software is included in the Raspberry Pi 3 server. You don't need to download the program.
Instant experimental data. Our Simulation Tool runs simulations at high speed. In a few seconds you'll have your results.
Customizable parameters. You can modify your parameters and adapt them to your experiment, to obtain more precise results.
All-in-one. Our Simulation Tool includes several mathematical models, constitutive and inducible, in a single code and solves them particularizing for each Printeria genetic construction.
Would you like to try the Simulation Tool? Go to our Printeria Controller site and discover all the possibilities offered by our software.
What are you waiting for to start discovering it?
References
Picó, J., Vignoni, A., Picó-Marco, E., & Boada, Y. (2015). Modelado de sistemas bioquímicos: De la ley de acción de masas a la aproximación lineal del ruido. Revista Iberoamericana de Automática e Informática Industrial RIAI, 12(3), 241-252.
Y. Boada, A. Vignoni, and J. Picó. (2017). Engineered control of genetic variability reveals interplay among quorum sensing, feedback regulation, and biochemical noise. ACS Synthetic Biology, 6(10):1903–1912, 2017a.
Segel, L. A., & Slemrod, M. (1989). The quasi-steady-state assumption: a case study in perturbation. SIAM review, 31(3), 446-477.
Boada, Y., Vignoni, A., Reynoso-Meza, G., & Picó, J. (2016). Parameter identification in synthetic biological circuits using multi-objective optimization. Ifac-Papersonline, 49(26), 77-82.
R. Milo and R. Phillips. Cell Biology by the Numbers. First edition, 2015. ISBN9780815345374.
Boada, Y., Vignoni, A., & Picó, J. (2017). Reduction of population variability in protein expression: A control engineering approach. Actas de las XXXVIII Jornadas de Automática.
U. Alon. An Introduction to Systems Biology. Desing Principles of Biological Circuits. Champan and Hall/CRC, Edition, 2007.
Schleif, R. (2000). Regulation of the L-arabinose operon of Escherichia coli. Trends in Genetics, 16(12), 559-565.
Boada, Y. (2018). A systems engineering approach to model, tune and test synthetic gene circuits. PhD. Thesis, Universitat Politècnica de València.
N. E. Buchler, U. Gerland, and T. Hwa. Nonlinear protein degradation and the function of genetic circuits. Proceedings of the National Academy of Sciences of the United States of America, 102(27):9559–9564, 2005.