PROMOTER TOOL
Since we wanted to design our Listeria detection system to work both E. coli (for testing) and in Lactococcus lactis (for the industrial application), we wanted to select a promoter that would work well in both species. We came across a paper by Jensen and Hammer, who designed a series of 37 constitutive promoters and characterised their activity in both E. coli and L. lactis using a beta galactosidase assay. They provided an image of aligned sequences juxtaposed with their activity in both species, and this made us wonder whether we could selectively alter certain parts of these sequences to optimise their activity for our purposes. We realised this would mean designing a more active constitutive promoter for our agrC and agrA sensing components, as we want these to be expressed all the time and in large amounts. However, this tool could be used by other iGEM teams who may want a promoter associated with a lower constitutive expression to keep readthrough expression levels at a low level (for more information, see our Collaborations Page)
How does our model work?
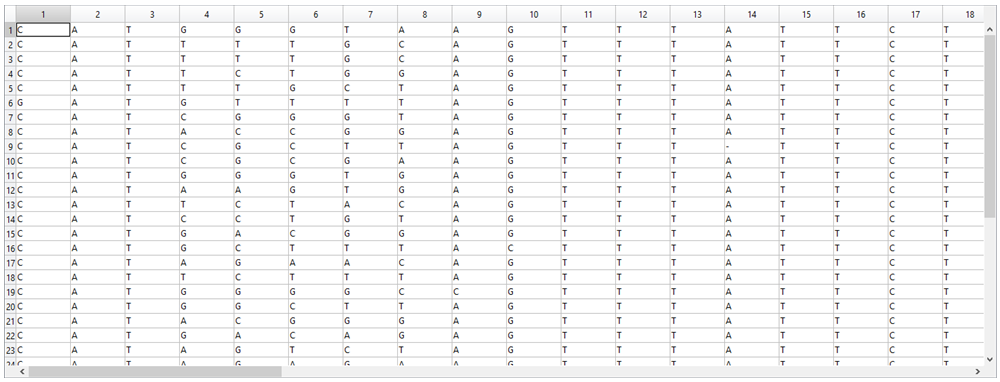
1. Each sequence was hand-typed into an Excel file and, for ease of comparison, the sequences were aligned and if there was a deletion, it was indicated with “-“.
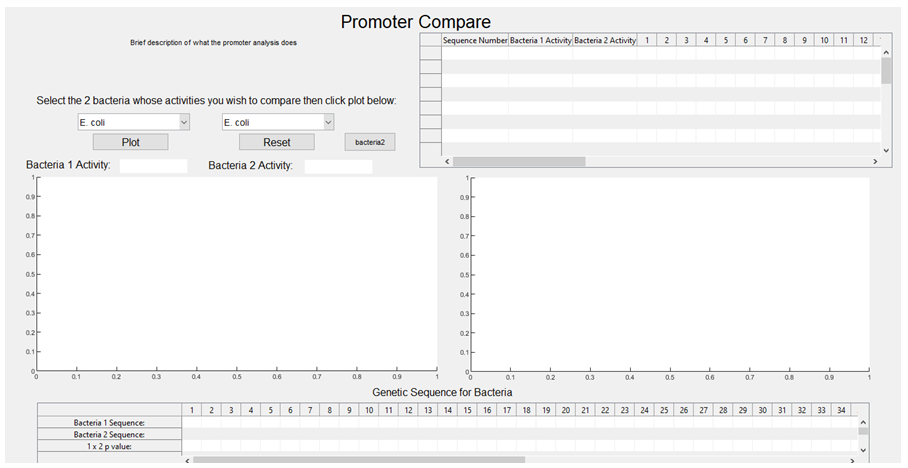
2. Once the program is started in Matlab, the first pop up window you see is this:
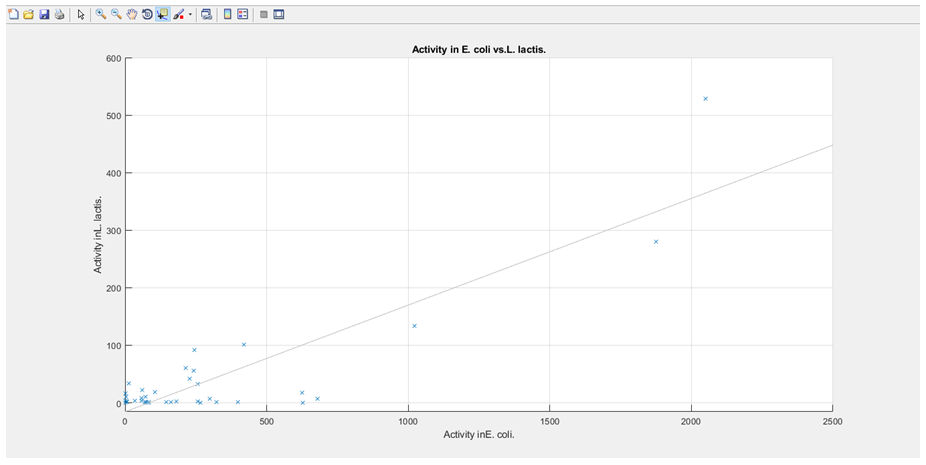
3. The activities associated with each sequence are plotted against each other, with E. coli on the x-axis and L. lactis on the y-axis (the graph is then stored and will pop up upon the user selecting E. coli and L. lactis from the graphical user interface (GUI) dropdown boxes, with a regression line also plotted).
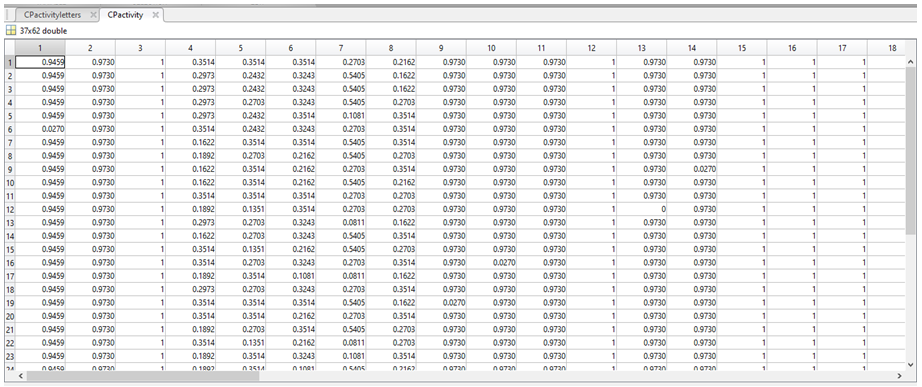
4. We determined the frequency of each nucleotide in a particular column (e.g.: in column 1 94.59% of nucleotides were a “C”, 2.7% were “G”, 2.7% were a “T”, and there were no “A” or “-“).
5. The end result is a large table comparing the frequencies of each nucleotide in a particular position (column) across the 37 sequences, which we called CPactivity.
6. We then used the following equation:
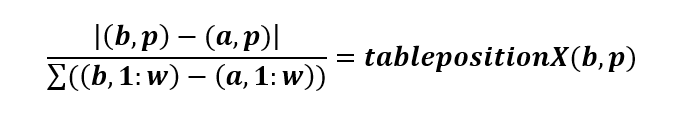
(b, p) = coordinate 1, where b can be any value row index between 1 and 37 (i.e. the total number of sequences) and p is any column index between 1 and 60
(a, p) = coordinate 2, where a can be any value row index between 1 and 37 (i.e. the total number of sequences) and does not have to be equal to b; however, if b=a, a NaN value will be generated.
(b, 1:w) = the sum of the values in row b
(a, 1:w) = the sum of the values in row a
Note: coordinates are written as (row, column)
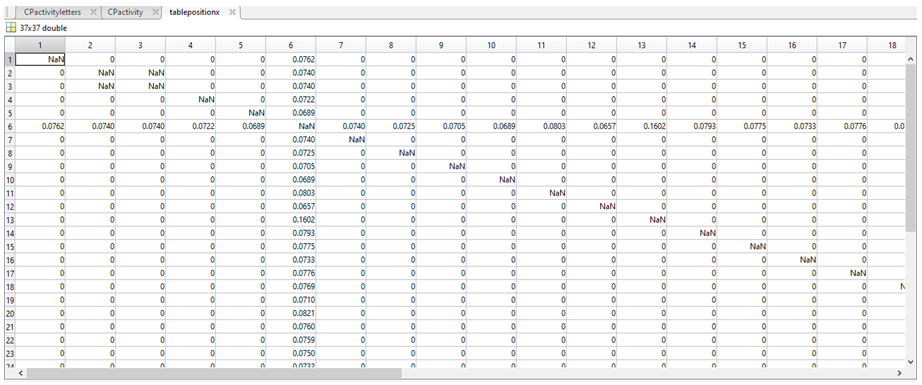
In MatLab, we used this equation to compare sequence 1 to itself and every other sequence, then sequence 2 to itself and every other sequence and so on. This calculation resulted in the less common bases being awarded a higher weight, as we theorised that if the activity is changing across all sequences, yet an area is conserved (i.e. all T’s) then this region is less likely to be responsible for any changes between the overall sequence activity. The resulting values were then stored in a set of new variables (each a 37 by 37 table). The table for column 1 is called tablepositionX, which is shown below.
7. The non zero value means from tablepositionX were then collated into a new variable called averageactivitychange, to assign a mean “weight” associated with each nucleotide.
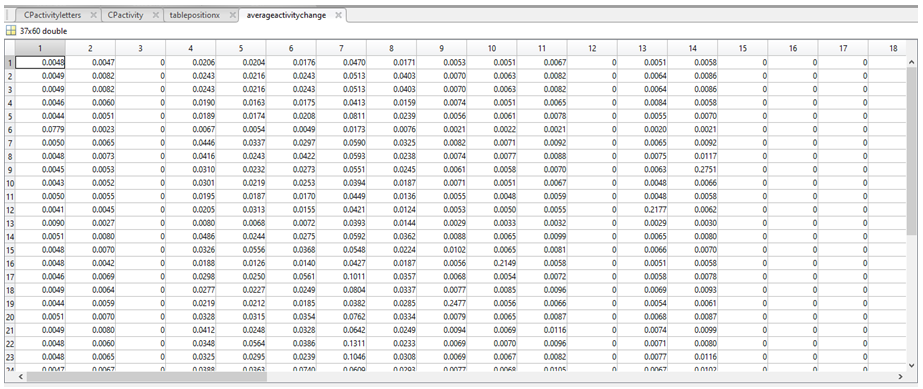
8. Each base is now associated with a comparative frequency (as a fraction), with the less common bases having a higher weighting, (the sum of each row is 1 at this point in time). We then used the following equations:
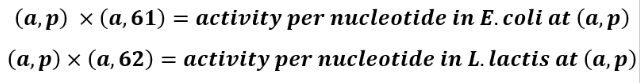
a can be any row indices between 1 and 37
p can be any column indices between 1 and 60.
column 61 contains the activities of each promoter sequence in E. coli
column 62 contains the activities of each promoter sequence in L. lactis
9. We stored the variable “activity per nucleotide in E. coli” as a 37 by 60 table called activitychangebacteria1, and the variable “activity per nucleotide in L. lactis” also as a 37 by 60 table called activitychangebacteria2.
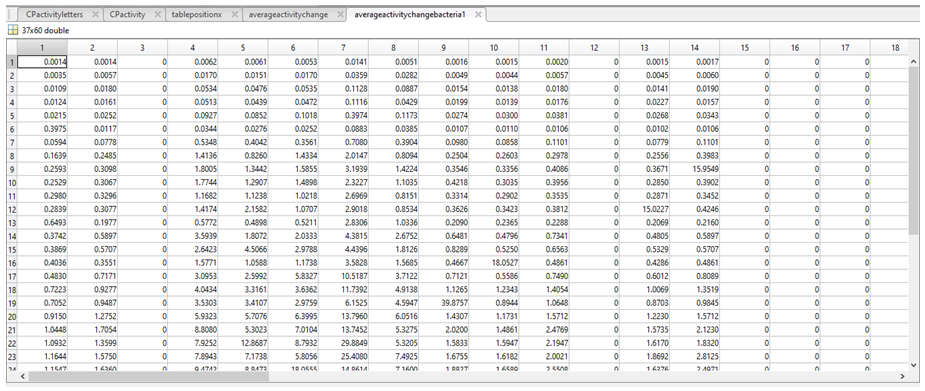
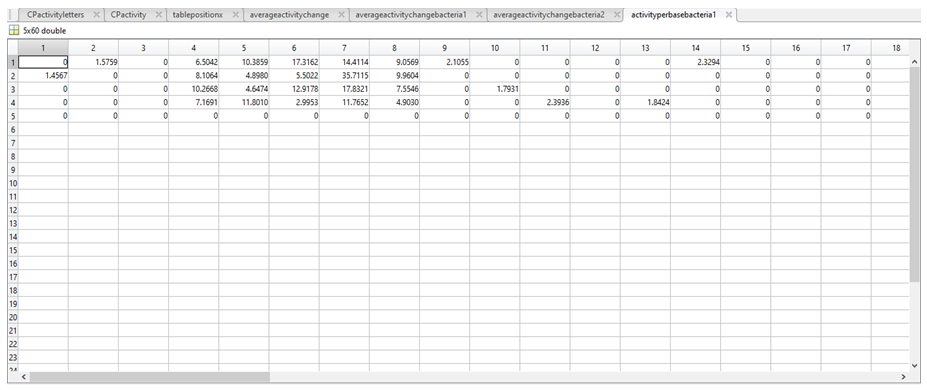
10. We then aimed to acquire a value per nucleotide in a given column (p) of activitychangebacteria1 and activitychangebacteria2 (to tell us the relative activity associated with having a A in position 1 of the promoter, for example). To do this we first had to verify the presence of a particular nucleotide (N*) in column p, followed by the total number of a given nucleotide in column p (length(N)). If the length(N) was greater than 1 (i.e there is more than 1 of a given nucleotide in column p), then a mean activity of every “N” in activitychangebacteria1 (for column p) and activitychangebacteria2 (for column p) was calculated and stored in either averageactivityperbasebacteria1 or averageactivityperbasebacteria2. If length(N) was less than 1, a value of 0 was assigned to every N in column p and stored in either averageactivityperbasebacteria1 and averageactivityperbasebacteria2.
*NOTE: “N” refers to “A”, “C”, “G”, “T”, or “-”
p can be any column index between 1 and 60
11. Each row in averageactivityperbasebacteria1 (first image below) and averageactivityperbasebacteria2 (second image below) corresponds to a nucleotide (1 = A, 2 = C, 3 = G, 4 = T, 5 = “-“).
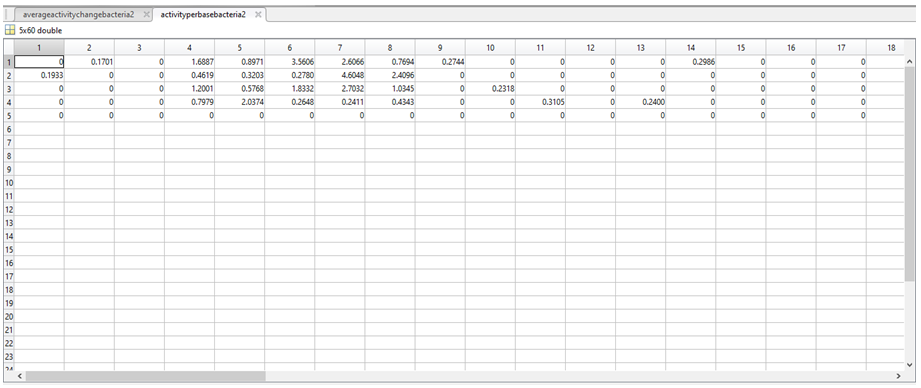
12. To determine if there was any significant difference between the activities assigned in the two above variables, a t-test was carried out in MatLab to produce a number between 0 and 1 representing the statistical significance of the difference between the above two variables. The results of the t-test were stored in a further two variables called siglev1 and siglev2. Each row in siglev1 and siglev2 also corresponds to a nucleotide (1 = A, 2 = C, 3 = G, 4 = T, 5 = “-“).
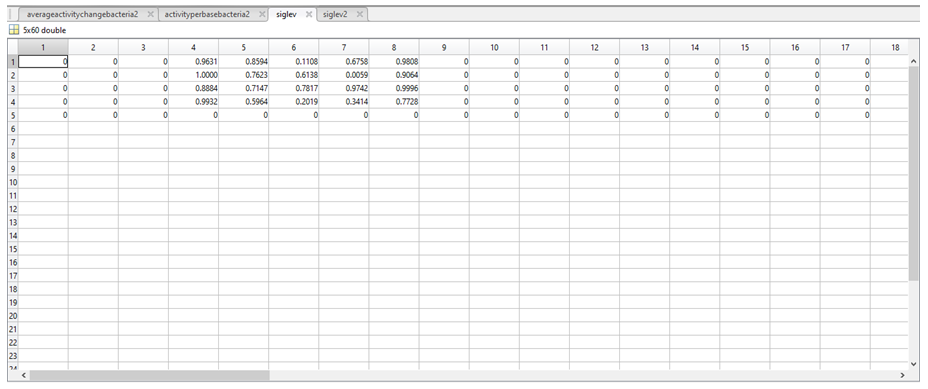
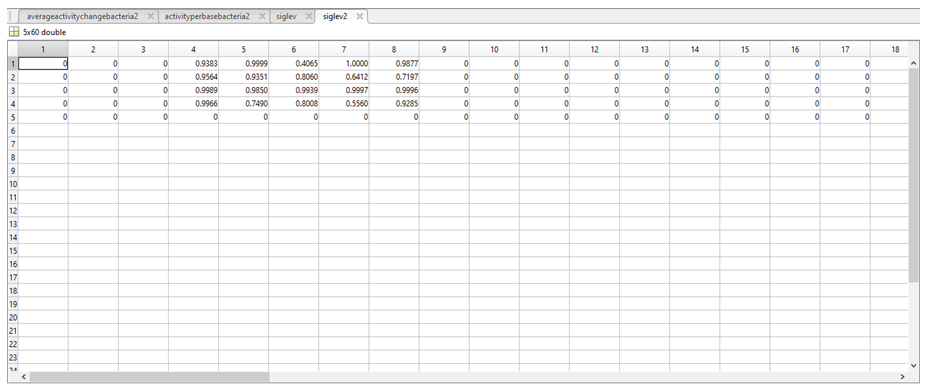
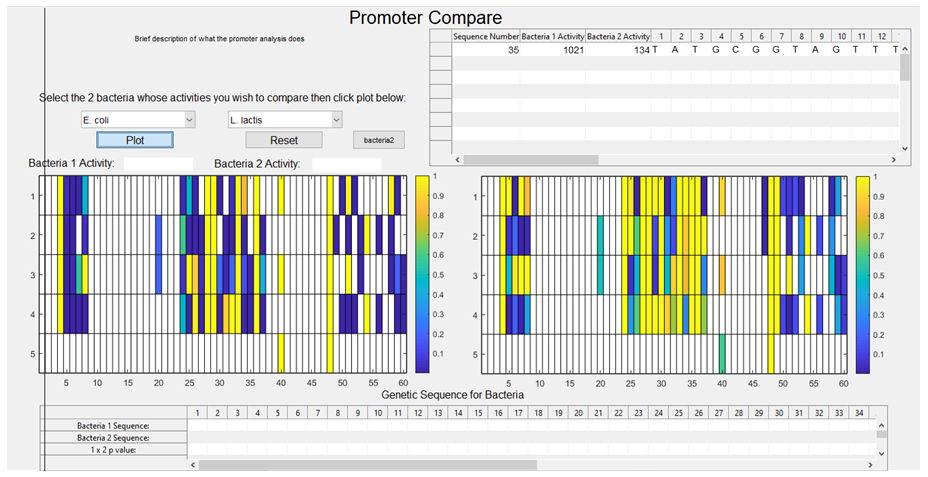
13. The siglev variables are then visualised on the GUI using the imagesc function, (insert image of GUI plots), with white areas indicating a lack of data to carry out the t test at this particular position, and a gradient from blue to orange, with blue representing the areas of highest significance and areas of orange representing areas of lower significance.
Discussion
The purpose behind designing this tool in the GUI app in MatLab was so that a user could, with ease, design a new synthetic promoter using pre-existing data on characterised promoters within a particular (pair of) species. To that end, we wanted our program to be able to display the activity associated with a particular base in a particular column upon the user left-clicking a particular cell from the imagesc plot. This would allow the user to determine the effect on the overall activity of the sequence if a substitution took place at a region of high significance. We then wanted a user to be able to design their new sequence within our program upon a right-click, storing the nucleotide associated with the particular cell the user selected.
The purpose of having bacterial selection drop down options on the GUI was so that, in the future, the sequences may have their activities measured across other species and this data could be integrated into our model. We also added a function to allow the user to select a sequence of interest (say, one that has high activity in both species being compared) and store this sequence for reference when designing the new sequence on the GUI. Additionally, we created the variables W and L which correspond, respectively, to the number of columns and rows in the initial Excel file, so that, in the future, additional sequences of variable lengths (not just 60nt) could be integrated into our model.
Promoter Tool Code
function varargout = promoteranalysisgui(varargin)
% PROMOTERANALYSISGUI MATLAB code for promoteranalysisgui.fig
% PROMOTERANALYSISGUI, by itself, creates a new PROMOTERANALYSISGUI or raises the existing
% singleton*.
%
% H = PROMOTERANALYSISGUI returns the handle to a new PROMOTERANALYSISGUI or the handle to
% the existing singleton*.
%
% PROMOTERANALYSISGUI('CALLBACK',hObject,eventData,handles,...) calls the local
% function named CALLBACK in PROMOTERANALYSISGUI.M with the given input arguments.
%
% PROMOTERANALYSISGUI('Property','Value',...) creates a new PROMOTERANALYSISGUI or raises the
% existing singleton*. Starting from the left, property value pairs are
% applied to the GUI before promoteranalysisgui_OpeningFcn gets called. An
% unrecognized property name or invalid value makes property application
% stop. All inputs are passed to promoteranalysisgui_OpeningFcn via varargin.
%
% *See GUI Options on GUIDE's Tools menu. Choose "GUI allows only one
% instance to run (singleton)".
%
% See also: GUIDE, GUIDATA, GUIHANDLES
% Edit the above text to modify the response to help promoteranalysisgui
% Last Modified by GUIDE v2.5 11-Sep-2018 14:21:33
% Begin initialization code - DO NOT EDIT
gui_Singleton = 1;
gui_State = struct('gui_Name', mfilename, ...
'gui_Singleton', gui_Singleton, ...
'gui_OpeningFcn', @promoteranalysisgui_OpeningFcn, ...
'gui_OutputFcn', @promoteranalysisgui_OutputFcn, ...
'gui_LayoutFcn', [] , ...
'gui_Callback', []);
if nargin && ischar(varargin{1})
gui_State.gui_Callback = str2func(varargin{1});
end
if nargout
[varargout{1:nargout}] = gui_mainfcn(gui_State, varargin{:});
else
gui_mainfcn(gui_State, varargin{:});
end
% End initialization code - DO NOT EDIT
% --- Executes just before promoteranalysisgui is made visible.
function promoteranalysisgui_OpeningFcn(hObject, eventdata, handles, varargin)
% This function has no output args, see OutputFcn.
% hObject handle to figure
% eventdata reserved - to be defined in a future version of MATLAB
% handles structure with handles and user data (see GUIDATA)
% varargin command line arguments to promoteranalysisgui (see VARARGIN)
% Choose default command line output for promoteranalysisgui
handles.output = hObject;
% Update handles structure
guidata(hObject, handles);
% UIWAIT makes promoteranalysisgui wait for user response (see UIRESUME)
% uiwait(handles.figure1);
% UPDATE DROP DOWN MENUS:
set(handles.figure1, 'units', 'normalized', 'position', [0 0 1 1])
[~,CPactivityletters,CPactivity] = xlsread('Cpactivity.xlsx');
CPactivity(1,:) = [];
bacterianames = CPactivityletters(1,61 : end)';
set(handles.popupmenu1,'String',bacterianames);
set(handles.popupmenu2,'String',bacterianames);
% --- Outputs from this function are returned to the command line.
function varargout = promoteranalysisgui_OutputFcn(hObject, eventdata, handles)
% varargout cell array for returning output args (see VARARGOUT);
% hObject handle to figure
% eventdata reserved - to be defined in a future version of MATLAB
% handles structure with handles and user data (see GUIDATA)
% Get default command line output from handles structure
varargout{1} = handles.output;
function edit1_Callback(hObject, eventdata, handles)
% hObject handle to edit1 (see GCBO)
% eventdata reserved - to be defined in a future version of MATLAB
% handles structure with handles and user data (see GUIDATA)
% Hints: get(hObject,'String') returns contents of edit1 as text
% str2double(get(hObject,'String')) returns contents of edit1 as a double
% --- Executes during object creation, after setting all properties.
function edit1_CreateFcn(hObject, eventdata, handles)
% hObject handle to edit1 (see GCBO)
% eventdata reserved - to be defined in a future version of MATLAB
% handles empty - handles not created until after all CreateFcns called
% Hint: edit controls usually have a white background on Windows.
% See ISPC and COMPUTER.
if ispc && isequal(get(hObject,'BackgroundColor'), get(0,'defaultUicontrolBackgroundColor'))
set(hObject,'BackgroundColor','white');
end
function edit2_Callback(hObject, eventdata, handles)
% hObject handle to edit2 (see GCBO)
% eventdata reserved - to be defined in a future version of MATLAB
% handles structure with handles and user data (see GUIDATA)
% Hints: get(hObject,'String') returns contents of edit2 as text
% str2double(get(hObject,'String')) returns contents of edit2 as a double
% --- Executes during object creation, after setting all properties.
function edit2_CreateFcn(hObject, eventdata, handles)
% hObject handle to edit2 (see GCBO)
% eventdata reserved - to be defined in a future version of MATLAB
% handles empty - handles not created until after all CreateFcns called
% Hint: edit controls usually have a white background on Windows.
% See ISPC and COMPUTER.
if ispc && isequal(get(hObject,'BackgroundColor'), get(0,'defaultUicontrolBackgroundColor'))
set(hObject,'BackgroundColor','white');
end
% --- Executes on button press in pushbutton3.
function pushbutton3_Callback(hObject, eventdata, handles)
% hObject handle to pushbutton3 (see GCBO)
% eventdata reserved - to be defined in a future version of MATLAB
% handles structure with handles and user data (see GUIDATA)
% --- Executes on button press in pushbutton4.
function pushbutton4_Callback(hObject, eventdata, handles)
% hObject handle to pushbutton4 (see GCBO)
% eventdata reserved - to be defined in a future version of MATLAB
% handles structure with handles and user data (see GUIDATA)
% --- Executes on button press in pushbutton1.
function pushbutton1_Callback(hObject, eventdata, handles)
% hObject handle to pushbutton1 (see GCBO)
% eventdata reserved - to be defined in a future version of MATLAB
% handles structure with handles and user data (see GUIDATA)
[~,CPactivityletters,CPactivity] = xlsread('Cpactivity.xlsx');
CPactivity(1,:) = [];
bacterianames = CPactivityletters(1,61 : end)';
activities = cell2mat(CPactivity(:,61 : end));
bacteria1choice = get(handles.popupmenu1,'Value')
bacteria2choice = get(handles.popupmenu2,'Value')
bacteria1name = bacterianames {bacteria1choice};
bacteria2name = bacterianames {bacteria2choice};
bacteria1column = find(strcmp(CPactivityletters(1,61 : end),bacteria1name));
bacteria2column = find(strcmp(CPactivityletters(1,61 : end),bacteria2name));
bacteria1activity = activities(:,bacteria1column);
bacteria2activity = activities(:,bacteria2column);
nucleotides = {'A', 'C', 'G', 'T', '-'};
CPactivityletters(1,:) = [];
m = size(CPactivity); % Done to achieve a matrix of "37" "62"
W = m(2);
L = m(1); % Used to select the 37 from the above matrix
occurences = zeros(L,W-2); % Generates a empty matrix, which can be used to store the commanality of the nucleotide at this position (ie - in this column) as a value between 0 and 1
for k = 1 : 60
for j = 1 : length(nucleotides)
occurences (j,k) = sum((double(strcmp(CPactivity(1:end,k), nucleotides{1,j}))) == 1)/L;
end
end
for q = 1 : 60
for r = 1 : L
if double(strcmp( CPactivity{r,q}, 'A')) == 1
CPactivity{r,q} = occurences(1,q);
elseif double(strcmp( CPactivity{r,q}, 'C')) == 1
CPactivity{r,q} = occurences(2,q);
elseif double(strcmp( CPactivity{r,q}, 'G')) == 1
CPactivity{r,q} = occurences(3,q);
elseif double(strcmp( CPactivity{r,q}, 'T')) == 1
CPactivity{r,q} = occurences(4,q);
else
CPactivity{r,q} = occurences(5,q);
end
end
end
CPactivity = cell2mat(CPactivity);
tablepositionx = zeros (L,L); %tablepositionx is the collection of changing probablilities (in relation to the likelihood of it causing change in activity) between sequences at position x L = number of rows
averageactivitychange = zeros (L,W-2);
for p = 1 : 60
for b = 1 : L % loop through the rows one by one
for a = 1 : L
tablepositionx(b,a) = abs(CPactivity(b,p)-CPactivity(a,p))/(sum(abs(CPactivity(b,1:end-2) - CPactivity(a,1:end-2))));
end
end
for t = 1 : L
averageactivitychange(t,p) = nanmean(tablepositionx(t,:)); % I want to be able to chose the mean of only the fully filled rows
end
end
[row,col] = find(averageactivitychange==0);
figure (1)
scatter(CPactivity(1:end,61),CPactivity(1:end,62),'x');
lsline
datacursormode on
grid on
title (['Activity in ' bacteria1name ' vs.' bacteria2name '.'])
xlabel (['Activity in' bacteria1name '.'])
ylabel (['Activity in' bacteria2name '.'])
pause
[xclicks,yclicks] = ginput;
c = length(xclicks);
sequencesofinterest = cell(c, W+1);
for d = 1 : c
[~,index] = min((CPactivity(:,61)-xclicks(d,1)).^2+(CPactivity(:,62)-yclicks(d,1)).^2);
sequencesofinterest{d,1} = index;
sequencesofinterest(d,2:3) = num2cell(CPactivity(index,W-1 : W));
sequencesofinterest(d,4:end) = CPactivityletters(index,1:W-2);
end
set(handles.uitable2,'data',sequencesofinterest)
figure (2)
title (['Activity changes in' bacteria1name 'and' bacteria2name '.'])
imagesc(averageactivitychange);
colorbar
hold on
g_y=[0.5:1:L + 0.5]; % user defined grid Y [start:spaces:end]
g_x=[0.5:1:(W-2) + 0.5]; % user defined grid X [start:spaces:end]
for i=1:length(g_x)
plot([g_x(i) g_x(i)],[g_y(1) g_y(end)],'k') %y grid lines
hold on
end
for i=1:length(g_y)
plot([g_x(1) g_x(end)],[g_y(i) g_y(i)],'k') %x grid lines
hold on
end
set(gca,'xtick', linspace(1,W-2,floor((W-2)/5)+2), 'ytick', linspace(1,L,floor(L/5)));
activitychangebacteria1 = zeros(L,W-2);
activitychangebacteria2 = zeros(L,W-2);
for a = 1 : L
activitychangebacteria1 (a,1:end) = averageactivitychange(a,1:end) * CPactivity(a,61);
activitychangebacteria2 (a,1:end) = averageactivitychange(a,1:end) * CPactivity(a,62);
end
% Calculate mean activity change per column for each bacteria:
averageactivitychangebacteria1 = mean(activitychangebacteria1);
averageactivitychangebacteria2 = mean(activitychangebacteria2);
% Calculate difference between activity changes and mean activity change per column
for i = 1 : W-2
activitychangebacteria1(1:end,i) = activitychangebacteria1(1:end,i) - averageactivitychangebacteria1(1,i);
activitychangebacteria2(1:end,i) = activitychangebacteria2(1:end,i) - averageactivitychangebacteria2(1,i);
end
% looping though each column to calculate average activity of each letter:
activityperbasebacteria1 = zeros (5,W-2); % Activity per base created - 5 x 60 matrix
activityperbasebacteria2 = zeros (5,W-2); % Activity per base created - 5 x 60 matrix
for r = 1 : W-2
% if no average activity change is detected for column r then set all of activityperbasebacteria1(:,r) to 0
if averageactivitychangebacteria1(:,r) == 0
activityperbasebacteria1(:,r) = 0;
end
if averageactivitychangebacteria2(:,r) == 0
activityperbasebacteria2(:,r) = 0;
end
% Find the row numbers (INDICES) where the 5 bases appear:
idxA = find(strcmp(CPactivityletters(:,r),'A') == 1);
idxC = find(strcmp(CPactivityletters(:,r),'C') == 1);
idxG = find(strcmp(CPactivityletters(:,r),'G') == 1);
idxT = find(strcmp(CPactivityletters(:,r),'T') == 1);
idxdash = find(strcmp(CPactivityletters(:,r),'-') == 1);
if isempty(idxA) == 1 || length(idxA) == 1
activityperbasebacteria1(1,r) = 0;
activityperbasebacteria2(1,r) = 0;
else
activityperbasebacteria1(1,r) = mean(activitychangebacteria1(idxA,r));
activityperbasebacteria2(1,r) = mean(activitychangebacteria2(idxA,r));
end
if isempty(idxC) == 1 || length(idxC) == 1
activityperbasebacteria1(2,r) = 0;
activityperbasebacteria2(2,r) = 0;
else
activityperbasebacteria1(2,r) = mean(activitychangebacteria1(idxC,r));
activityperbasebacteria2(2,r) = mean(activitychangebacteria2(idxC,r));
end
if isempty(idxG) == 1 || length(idxG) == 1
activityperbasebacteria1(3,r) = 0;
activityperbasebacteria2(3,r) = 0;
else
activityperbasebacteria1(3,r) = mean(activitychangebacteria1(idxG,r));
activityperbasebacteria2(3,r) = mean(activitychangebacteria2(idxG,r));
end
if isempty(idxT) == 1 || length(idxT) == 1
activityperbasebacteria1(4,r) = 0;
activityperbasebacteria2(4,r) = 0;
else
activityperbasebacteria1(4,r) = mean(activitychangebacteria1(idxT,r));
activityperbasebacteria2(4,r) = mean(activitychangebacteria2(idxT,r));
end
if isempty(idxdash) == 1 || length(idxdash) == 1
activityperbasebacteria1(5,r) = 0;
activityperbasebacteria2(5,r) = 0;
else
activityperbasebacteria1(5,r) = mean(activitychangebacteria1(idxdash,r));
activityperbasebacteria2(5,r) = mean(activitychangebacteria2(idxdash,r));
end
end
STATS STUFF:
chibacteria1 = zeros(5,60);
for a = 1 : 60
for b = 1 : 5
if activityperbasebacteria1(:,a) == 1
else
if activityperbasebacteria1 (b,a) == 0
chibacteria1(b,a) = 0;
else
meanofcolumn = mean(activityperbasebacteria1(find(activityperbasebacteria1(:,a)~=0),a));
chibacteria1(b,a) = ((activityperbasebacteria1(b,a) - meanofcolumn) .^ 2)/ meanofcolumn;
end
end
end
end
siglev1 = zeros(5,60);
for b = 1 : 5
for a = 1 : 60
for i = chibacteria1(b,a)
if chibacteria1(b,a) == 0
else
siglev1(b,a) = 1 - chi2cdf(i,nnz(chibacteria1(:,a))-1);
end
end
end
end
% the above gives the significance level to which you can trust the result
% REPEAT FOR BACTERIA 2:
chibacteria2 = zeros(5,60);
for a = 1 : 60
for b = 1 : 5
if activityperbasebacteria2(:,a) == 1
else
if activityperbasebacteria2 (b,a) == 0
chibacteria2(b,a) = 0;
else
meanofcolumn = mean(activityperbasebacteria2(find(activityperbasebacteria2(:,a)~=0),a));
chibacteria2(b,a) = ((activityperbasebacteria2(b,a) - meanofcolumn) .^ 2)/ meanofcolumn;
end
end
end
end
siglev2 = zeros(5,60);
for b = 1 : 5
for a = 1 : 60
for i = chibacteria2(b,a)
if chibacteria2(b,a) == 0
else
siglev2(b,a) = 1 - chi2cdf(i,nnz(chibacteria2(:,a))-1);
end
end
end
end
siglevbacteriacombine = zeros(11,60);
siglevbacteriacombine(1:5,1:60) = siglev1;
siglevbacteriacombine(6,1:60) = 2;
siglevbacteriacombine(7:11,1:60) = siglev2;
siglevbacteriacombine(siglevbacteriacombine == 0) = NaN;
[h,p] = ttest(siglev1,siglev2);
p(isnan(p))=1;
pstring = num2cell(p);
PLOT STUFF:
axes(handles.axes1);
imagesc(siglevbacteriacombine(1:5,1:60),'AlphaData',~isnan((siglevbacteriacombine(1:5,1:60))));
colorbar
hold on
for i=1:length(g_x)
plot([g_x(i) g_x(i)],[g_y(1) g_y(end)],'k') %y grid lines
hold on
end
for i=1:length(g_y)
plot([g_x(1) g_x(end)],[g_y(i) g_y(i)],'k') %x grid lines
hold on
end
set(gca,'xtick', linspace(5,W-2,(W-2) / 5), 'ytick', linspace(1,L,L));
axes(handles.axes2)
imagesc(siglevbacteriacombine(7:11,1:60),'AlphaData',~isnan((siglevbacteriacombine(7:11,1:60))));
colorbar
hold on
for i=1:length(g_x)
plot([g_x(i) g_x(i)],[g_y(1) g_y(end)],'k') %y grid lines
hold on
end
for i=1:length(g_y)
plot([g_x(1) g_x(end)],[g_y(i) g_y(i)],'k') %x grid lines
hold on
end
set(gca,'xtick', linspace(5,W-2,(W-2)/5), 'ytick', linspace(1,L,L));
USER INPUT BOX TO GATHER HOW MANY BASES USER WILL SELECT:
% prompt = {'Enter number of bases to select for bacteria 1:','Enter number of bases to select for bacteria 2:'};
% titlebox ='Base Selection';
% dims = [1 35];
% answer = inputdlg(prompt,titlebox,dims);
% numberbasestoselectbacteria1 = str2num (answer{1,1});
% numberbasestoselectbacteria2 = str2num (answer{2,1});
% %% THIS IS ALL THE CRAP WHERE YOU CAN SELECT BOTH HEAT MAPS AT THE SAME TIME AND THE USER DOESNT HAVE TO KNOW HOW MANY LETTERS TO SELECT:
%
%
% %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%
% positionaxes1 = get(handles.axes1, 'Position');
%
% axes1x1 = positionaxes1(1);
% axes1y1 = positionaxes1(2);
% axes1width = positionaxes1(3);
% axes1height = positionaxes1(4);
%
%
% % Gather coordinates for 4 corners of axes 1 and 2:
%
% axes1x2 = axes1x1 + axes1width;
% axes1y2 = axes1y1 + axes1height;
%
%
% positionaxes2 = get(handles.axes2, 'Position');
%
% axes2x1 = positionaxes2(1);
% axes2y1 = positionaxes2(2);
% axes2width = positionaxes2(3);
% axes2height = positionaxes2(4);
%
%
% axes2x2 = axes2x1 + axes2width;
% axes2y2 = axes2y1 + axes2height;
%
% %
% %
% % w = 0;
% %
% %
% % while (w == 0)
% %
% % for a = 1 : 1000
% %
% %
% %
% % Get current location of mouse
% %
% % set (gcf, 'WindowButtonMotionFcn', @mouseMove);
% %
% % c = get (gca, 'CurrentPoint');
% %
% % x = c(1,1);
% %
% % y = c(1,2);
% %
% %
% %
% %
% %
% [x(a),y(a),button(a)] = ginput(1); % get points the user clicked
%
% generalpoints(a,1:2) = get(handles.figure1, 'currentpoint');
%
% generalx = generalpoints(a,1);
%
% generaly = generalpoints(a,2);
%
% % end
% %
% %
% %
%
%
% if generalx <= axes1x2 && generalx >= axes1x1 && generaly <= axes1y2 && generaly >= axes1y1
%
% bacteria1x = ceil (x(a)-0.5);
%
% bacteria1y = ceil (y(a)-0.5);
%
% k = 1;
%
%
% if button(a) == 1 && k == 1
%
% bacteria1letters (1,bacteria1x) = activityperbasebacteria1(bacteria1y, bacteria1x);
%
% %
% %
% % elseif button(a) == 3 && k == 1
% %
% % activitybacteria1 = activityperbasebacteria1(bacteria1y, bacteria1x);
% %
% set(handles.text14, 'String', bacteria1letters (1,bacteria1x))
% %
% %
% end
% %
% %
% %
% elseif generalx <= axes2x2 && generalx >= axes2x1 && generaly <= axes2y2 && generaly >= axes2y1
%
% bacteria2x = ceil (x(a)-0.5);
%
% bacteria2y = ceil (y(a)-0.5);
%
% k = 2;
%
%
% if button(a) == 1 && k == 2
%
% bacteria2letters(1,bacteria2x) = activityperbasebacteria2(bacteria2y, bacteria2x);
%
%
% % elseif button(a) == 3 && k == 2
% %
% % activitybacteria2 = activityperbasebacteria2(bacteria2y, bacteria2x);
% %
% set(handles.text15, 'String', bacteria2letters(1,bacteria2x))
%
% %
%
% end
% %
% end
%
% %
% % end
% %
% % end
activitybacteria1 = zeros(5,60);
activitybacteria2 = zeros(5,50);
% positionaxes1 = get(handles.axes1, 'Position');
%
% axes1x1 = positionaxes1(1);
% axes1y1 = positionaxes1(2);
% axes1width = positionaxes1(3);
% axes1height = positionaxes1(4);
%
%
% % Gather coordinates for 4 corners of axes 1 and 2:
%
% axes1x2 = axes1x1 + axes1width;
% axes1y2 = axes1y1 + axes1height;
%
%
% positionaxes2 = get(handles.axes2, 'Position');
%
% axes2x1 = positionaxes2(1);
% axes2y1 = positionaxes2(2);
% axes2width = positionaxes2(3);
% axes2height = positionaxes2(4);
%
%
% axes2x2 = axes2x1 + axes2width;
% axes2y2 = axes2y1 + axes2height;
w = 0;
while (w == 0)
positionaxes1 = get(handles.axes1, 'Position');
axes1x1 = positionaxes1(1);
axes1y1 = positionaxes1(2);
axes1width = positionaxes1(3);
axes1height = positionaxes1(4);
% Gather coordinates for 4 corners of axes 1 and 2:
axes1x2 = axes1x1 + axes1width;
axes1y2 = axes1y1 + axes1height;
positionaxes2 = get(handles.axes2, 'Position');
axes2x1 = positionaxes2(1);
axes2y1 = positionaxes2(2);
axes2width = positionaxes2(3);
axes2height = positionaxes2(4);
axes2x2 = axes2x1 + axes2width;
axes2y2 = axes2y1 + axes2height;
for a = 1 : 1000
c = get (gca, 'CurrentPoint');
x = c(1,1);
y = c(1,2);
hold on
[x(a),y(a),button(a)] = ginput(1); % get points the user clicked
generalpoints(a,1:2) = get(handles.figure1, 'currentpoint');
generalx = generalpoints(a,1);
generaly = generalpoints(a,2);
if generalx <= axes1x2 && generalx >= axes1x1 && generaly <= axes1y2 && generaly >= axes1y1
bacteria1x = ceil (x(a)-0.5);
bacteria1y = ceil (y(a)-0.5);
k = 1;
if button(a) == 3 && k == 1
activitybacteria1(bacteria1y,bacteria1x) = activityperbasebacteria1(bacteria1y, bacteria1x);
set(handles.text14, 'String', activitybacteria1 (bacteria1y,bacteria1x))
end
elseif generalx <= axes2x2 && generalx >= axes2x1 && generaly <= axes2y2 && generaly >= axes2y1
bacteria2x = ceil (x(a)-0.5);
bacteria2y = ceil (y(a)-0.5);
k = 2;
if button(a) == 3 && k == 2
activitybacteria2(bacteria2y,bacteria2x) = activityperbasebacteria2(bacteria2y, bacteria2x);
set(handles.text15, 'String', activitybacteria2(bacteria2y,bacteria2x))
else
end
end
end
hold off
end
%
% while (w==1)
%
% c = get (gca, 'CurrentPoint');
%
% x = c(1,1);
%
% y = c(1,2);
% transnucleotide = nucleotides';
% undernucleotide = repelem(transnucleotide,[1],[60]);
%
%
% bacteria1letters = cell(1,60);
%
% bacteria2letters = cell(1,60);
%
% [x1,y1] = ginput(60);
%
% [x2,y2] = ginput(60);
%
% % [x1,y1] = ginput(numberbasestoselectbacteria1);
% %
% % [x2,y2] = ginput(numberbasestoselectbacteria2);
%
%
% bacteria1x = ceil (x1-0.5);
%
% bacteria1y = ceil (y1-0.5);
%
%
%
% for m = 1 : length(bacteria1x)
%
% bacteria1letters{1,bacteria1x(m)} = undernucleotide{bacteria1y(m),bacteria1x(m)};
%
% end
%
%
%
%
% bacteria1empty = find(cellfun('isempty',bacteria1letters)); % find empty cells
%
% bacteria1letters(bacteria1empty) = {'NA'};
%
% bacteria1sequence = strjoin(string (bacteria1letters));
%
%
% %%%%%%%%
%
%
% bacteria2x = ceil (x2-0.5);
%
% bacteria2y = ceil (y2-0.5);
%
%
%
% for n = 1 : length(bacteria2x)
%
% bacteria2letters{1,bacteria2x(n)} = undernucleotide{bacteria2y(n),bacteria2x(n)};
%
% end
%
%
%
%
% bacteria2empty = find(cellfun('isempty',bacteria2letters)); % find empty cells
%
% bacteria2letters(bacteria2empty) = {'NA'};
%
% bacteria2sequence = strjoin(string (bacteria2letters));
%
%
% % Create a new variable "sequencesandpvalues" that contains
% % user selected sequences and p values:
%
% sequencesandpvalues = cell(3,60);
%
% sequencesandpvalues(1,:) = bacteria1letters
% sequencesandpvalues(2,:) = bacteria2letters
% sequencesandpvalues(3,:) = pstring;
%
%
% set(handles.uitable3, 'data', sequencesandpvalues)
% end
% end
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
% LET USER SELECT BASES WHOSE ACTIVITIES THEY WANT TO INVESTIGATE:
% select for 1st heat map for bacteria 1:
w=1;
while (w==1)
positionaxes1 = get(handles.axes1, 'Position');
axes1x1 = positionaxes1(1);
axes1y1 = positionaxes1(2);
axes1width = positionaxes1(3);
axes1height = positionaxes1(4);
% Gather coordinates for 4 corners of axes 1 and 2:
axes1x2 = axes1x1 + axes1width;
axes1y2 = axes1y1 + axes1height;
positionaxes2 = get(handles.axes2, 'Position');
axes2x1 = positionaxes2(1);
axes2y1 = positionaxes2(2);
axes2width = positionaxes2(3);
axes2height = positionaxes2(4);
axes2x2 = axes2x1 + axes2width;
axes2y2 = axes2y1 + axes2height;
transnucleotide = nucleotides';
undernucleotide = repelem(transnucleotide,[1],[60]);
bacteria1letters = cell(1,60);
bacteria2letters = cell(1,60);
w=1;
c = get (gca, 'CurrentPoint');
x = c(1,1);
y = c(1,2);
[x1,y1,button(a)] = ginput(60);
[x2,y2,button(a)] = ginput(60);
% [x1,y1] = ginput(numberbasestoselectbacteria1);
%
% [x2,y2] = ginput(numberbasestoselectbacteria2);
bacteria1x = ceil (x1-0.5);
bacteria1y = ceil (y1-0.5);
% if button(a) == 1
for m = 1 : length(bacteria1x)
bacteria1letters{1,bacteria1x(m)} = undernucleotide{bacteria1y(m),bacteria1x(m)};
end
bacteria1empty = find(cellfun('isempty',bacteria1letters)); % find empty cells
bacteria1letters(bacteria1empty) = {'NA'};
bacteria1sequence = strjoin(string (bacteria1letters));
%%%%%%%%
bacteria2x = ceil (x2-0.5);
bacteria2y = ceil (y2-0.5);
for n = 1 : length(bacteria2x)
bacteria2letters{1,bacteria2x(n)} = undernucleotide{bacteria2y(n),bacteria2x(n)};
end
bacteria2empty = find(cellfun('isempty',bacteria2letters)); % find empty cells
bacteria2letters(bacteria2empty) = {'NA'};
bacteria2sequence = strjoin(string (bacteria2letters));
% Create a new variable "sequencesandpvalues" that contains
% user selected sequences and p values:
sequencesandpvalues = cell(3,60);
sequencesandpvalues(1,:) = bacteria1letters
sequencesandpvalues(2,:) = bacteria2letters
sequencesandpvalues(3,:) = pstring;
set(handles.uitable3, 'data', sequencesandpvalues)
end
% --- Executes on button press in pushbutton2.
function pushbutton2_Callback(hObject, eventdata, handles)
% hObject handle to pushbutton2 (see GCBO)
% eventdata reserved - to be defined in a future version of MATLAB
% handles structure with handles and user data (see GUIDATA)
function edit3_Callback(hObject, eventdata, handles)
% hObject handle to edit3 (see GCBO)
% eventdata reserved - to be defined in a future version of MATLAB
% handles structure with handles and user data (see GUIDATA)
% Hints: get(hObject,'String') returns contents of edit3 as text
% str2double(get(hObject,'String')) returns contents of edit3 as a double
% --- Executes during object creation, after setting all properties.
function edit3_CreateFcn(hObject, eventdata, handles)
% hObject handle to edit3 (see GCBO)
% eventdata reserved - to be defined in a future version of MATLAB
% handles empty - handles not created until after all CreateFcns called
% Hint: edit controls usually have a white background on Windows.
% See ISPC and COMPUTER.
if ispc && isequal(get(hObject,'BackgroundColor'), get(0,'defaultUicontrolBackgroundColor'))
set(hObject,'BackgroundColor','white');
end
function edit4_Callback(hObject, eventdata, handles)
% hObject handle to edit4 (see GCBO)
% eventdata reserved - to be defined in a future version of MATLAB
% handles structure with handles and user data (see GUIDATA)
% Hints: get(hObject,'String') returns contents of edit4 as text
% str2double(get(hObject,'String')) returns contents of edit4 as a double
% --- Executes during object creation, after setting all properties.
function edit4_CreateFcn(hObject, eventdata, handles)
% hObject handle to edit4 (see GCBO)
% eventdata reserved - to be defined in a future version of MATLAB
% handles empty - handles not created until after all CreateFcns called
% Hint: edit controls usually have a white background on Windows.
% See ISPC and COMPUTER.
if ispc && isequal(get(hObject,'BackgroundColor'), get(0,'defaultUicontrolBackgroundColor'))
set(hObject,'BackgroundColor','white');
end
% --- Executes on selection change in popupmenu1.
function popupmenu1_Callback(hObject, eventdata, handles)
% hObject handle to popupmenu1 (see GCBO)
% eventdata reserved - to be defined in a future version of MATLAB
% handles structure with handles and user data (see GUIDATA)
% Hints: contents = cellstr(get(hObject,'String')) returns popupmenu1 contents as cell array
% contents{get(hObject,'Value')} returns selected item from popupmenu1
list = get(handles.popupmenu1,'String');
idx1 = get(handles.popupmenu1,'Value');
bacteria1name = list{idx1};
set(handles.text6, 'String',bacteria1name)
% --- Executes on selection change in popupmenu2.
function popupmenu2_Callback(hObject, eventdata, handles)
% hObject handle to popupmenu2 (see GCBO)
% eventdata reserved - to be defined in a future version of MATLAB
% handles structure with handles and user data (see GUIDATA)
% Hints: contents = cellstr(get(hObject,'String')) returns popupmenu2 contents as cell array
% contents{get(hObject,'Value')} returns selected item from popupmenu2
list = get(handles.popupmenu1,'String');
idx2 = get(handles.popupmenu2,'Value');
bacteria2name = list{idx2};
set(handles.text7, 'String',bacteria2name)
% --- Executes during object creation, after setting all properties.
function popupmenu2_CreateFcn(hObject, eventdata, handles)
% hObject handle to popupmenu2 (see GCBO)
% eventdata reserved - to be defined in a future version of MATLAB
% handles empty - handles not created until after all CreateFcns called
% Hint: popupmenu controls usually have a white background on Windows.
% See ISPC and COMPUTER.
if ispc && isequal(get(hObject,'BackgroundColor'), get(0,'defaultUicontrolBackgroundColor'))
set(hObject,'BackgroundColor','white');
end
% --- Executes during object creation, after setting all properties.
function popupmenu1_CreateFcn(hObject, eventdata, handles)
% hObject handle to popupmenu1 (see GCBO)
% eventdata reserved - to be defined in a future version of MATLAB
% handles empty - handles not created until after all CreateFcns called
% Hint: popupmenu controls usually have a white background on Windows.
% See ISPC and COMPUTER.
if ispc && isequal(get(hObject,'BackgroundColor'), get(0,'defaultUicontrolBackgroundColor'))
set(hObject,'BackgroundColor','white');
end
function bacteria1_Callback(hObject, eventdata, handles)
% hObject handle to bacteria1 (see GCBO)
% eventdata reserved - to be defined in a future version of MATLAB
% handles structure with handles and user data (see GUIDATA)
% Hints: get(hObject,'String') returns contents of bacteria1 as text
% str2double(get(hObject,'String')) returns contents of bacteria1 as a double
% --- Executes during object creation, after setting all properties.
function bacteria1_CreateFcn(hObject, eventdata, handles)
% hObject handle to bacteria1 (see GCBO)
% eventdata reserved - to be defined in a future version of MATLAB
% handles empty - handles not created until after all CreateFcns called
% Hint: edit controls usually have a white background on Windows.
% See ISPC and COMPUTER.
if ispc && isequal(get(hObject,'BackgroundColor'), get(0,'defaultUicontrolBackgroundColor'))
set(hObject,'BackgroundColor','white');
end
function bacteria2_Callback(hObject, eventdata, handles)
% hObject handle to bacteria2 (see GCBO)
% eventdata reserved - to be defined in a future version of MATLAB
% handles structure with handles and user data (see GUIDATA)
% Hints: get(hObject,'String') returns contents of bacteria2 as text
% str2double(get(hObject,'String')) returns contents of bacteria2 as a double
% --- Executes during object creation, after setting all properties.
function bacteria2_CreateFcn(hObject, eventdata, handles)
% hObject handle to bacteria2 (see GCBO)
% eventdata reserved - to be defined in a future version of MATLAB
% handles empty - handles not created until after all CreateFcns called
% Hint: edit controls usually have a white background on Windows.
% See ISPC and COMPUTER.
if ispc && isequal(get(hObject,'BackgroundColor'), get(0,'defaultUicontrolBackgroundColor'))
set(hObject,'BackgroundColor','white');
end
function bacteria3_Callback(hObject, eventdata, handles)
% hObject handle to bacteria3 (see GCBO)
% eventdata reserved - to be defined in a future version of MATLAB
% handles structure with handles and user data (see GUIDATA)
% Hints: get(hObject,'String') returns contents of bacteria3 as text
% str2double(get(hObject,'String')) returns contents of bacteria3 as a double
% --- Executes during object creation, after setting all properties.
function bacteria3_CreateFcn(hObject, eventdata, handles)
% hObject handle to bacteria3 (see GCBO)
% eventdata reserved - to be defined in a future version of MATLAB
% handles empty - handles not created until after all CreateFcns called
% Hint: edit controls usually have a white background on Windows.
% See ISPC and COMPUTER.
if ispc && isequal(get(hObject,'BackgroundColor'), get(0,'defaultUicontrolBackgroundColor'))
set(hObject,'BackgroundColor','white');
end
function bacteria4_Callback(hObject, eventdata, handles)
% hObject handle to bacteria4 (see GCBO)
% eventdata reserved - to be defined in a future version of MATLAB
% handles structure with handles and user data (see GUIDATA)
% Hints: get(hObject,'String') returns contents of bacteria4 as text
% str2double(get(hObject,'String')) returns contents of bacteria4 as a double
% --- Executes during object creation, after setting all properties.
function bacteria4_CreateFcn(hObject, eventdata, handles)
% hObject handle to bacteria4 (see GCBO)
% eventdata reserved - to be defined in a future version of MATLAB
% handles empty - handles not created until after all CreateFcns called
% Hint: edit controls usually have a white background on Windows.
% See ISPC and COMPUTER.
if ispc && isequal(get(hObject,'BackgroundColor'), get(0,'defaultUicontrolBackgroundColor'))
set(hObject,'BackgroundColor','white');
end
% --- Executes on button press in pushbutton5.
function pushbutton5_Callback(hObject, eventdata, handles)
% hObject handle to pushbutton5 (see GCBO)
% eventdata reserved - to be defined in a future version of MATLAB
% handles structure with handles and user data (see GUIDATA)
% --- Executes on button press in togglebutton1.
function togglebutton1_Callback(hObject, eventdata, handles)
% hObject handle to togglebutton1 (see GCBO)
% eventdata reserved - to be defined in a future version of MATLAB
% handles structure with handles and user data (see GUIDATA)
% Hint: get(hObject,'Value') returns toggle state of togglebutton1.