Difference between revisions of "Team:Manchester/PromoterModel"
Ryan-Smith (Talk | contribs) |
Ryan-Smith (Talk | contribs) |
||
| Line 16: | Line 16: | ||
<br><p><b>2.</b> Once the program is started in Matlab, the first pop up window you see is this: <br><center><img src="https://static.igem.org/mediawiki/2018/7/77/T--Manchester--model2.png" width="700px" height="auto"/></p></center> | <br><p><b>2.</b> Once the program is started in Matlab, the first pop up window you see is this: <br><center><img src="https://static.igem.org/mediawiki/2018/7/77/T--Manchester--model2.png" width="700px" height="auto"/></p></center> | ||
| − | <br><p><b>3.</b> The activities associated with each sequence are plotted against each other, with E.coli on the x-axis and L. lactis on the y-axis (the graph is then stored and will pop up upon the user selecting E. coli and L. lactis from the GUI dropdown boxes, with a regression line also plotted). <br><center><img src="https://static.igem.org/mediawiki/2018/8/8c/T--Manchester--model3.png" width="700px" height="auto"/></ | + | <br><p><b>3.</b> The activities associated with each sequence are plotted against each other, with E.coli on the x-axis and L. lactis on the y-axis (the graph is then stored and will pop up upon the user selecting E. coli and L. lactis from the GUI dropdown boxes, with a regression line also plotted). <br><center><img src="https://static.igem.org/mediawiki/2018/8/8c/T--Manchester--model3.png" width="700px" height="auto"/></center> <br><center><img src="https://static.igem.org/mediawiki/2018/d/dc/T--Manchester--model4.png" width="700px" height="auto"/> </center><br><center><img src="https://static.igem.org/mediawiki/2018/1/1f/T--Manchester--model5.png" width="700px" height="auto"/> </p></center> |
| − | <br><p><b>4.</b> We determined the frequency of each nucleotide in a particular column (e.g.: in column 1 94.59% of nucleotides were a “C”, 2.7% were “G”, 2.7% were a “T”, and there were no “A” or “-“). <br><p><b>5.</b> The end result is a large table comparing the frequencies of each nucleotide in a particular position (column) across the 37 sequences, which we called CPactivity. </p> <br> <center><img src="https://static.igem.org/mediawiki/2018/8/8f/T--Manchester--model6.png" width="700px" height="auto"/> </p></ | + | <br><p><b>4.</b> We determined the frequency of each nucleotide in a particular column (e.g.: in column 1 94.59% of nucleotides were a “C”, 2.7% were “G”, 2.7% were a “T”, and there were no “A” or “-“). <br><p><b>5.</b> The end result is a large table comparing the frequencies of each nucleotide in a particular position (column) across the 37 sequences, which we called CPactivity. </p> <br> <center><img src="https://static.igem.org/mediawiki/2018/8/8f/T--Manchester--model6.png" width="700px" height="auto"/> </p></center> |
| − | <br><p><b>6.</b> We then used the following equation: <br> <center><img src="https://static.igem.org/mediawiki/2018/f/f6/T--Manchester--modelA.png" width="700px" height="auto"/> </ | + | <br><p><b>6.</b> We then used the following equation: <br> <center><img src="https://static.igem.org/mediawiki/2018/f/f6/T--Manchester--modelA.png" width="700px" height="auto"/> </center><br> (b, p) = coordinate 1, where b can be any value row index between 1 and 37 (i.e. the total number of sequences) and p is any column index between 1 and 60 <br> (a, p) = coordinate 2, where a can be any value row index between 1 and 37 (i.e. the total number of sequences) and does not have to be equal to b; however, if b=a, a NaN value will be generated. <br> (b, 1:w) = the sum of the values in row b <br> (a, 1:w) = the sum of the values in row a <br> <b>Note: coordinates are written as (row, column)</b></p> |
Revision as of 22:03, 17 October 2018
PROMOTER TOOL
Since we wanted to design our Listeria detection system to work both E. coli (for testing) and in Lactococcus lactis (for the industrial application), we wanted to select a promoter that would work well in both species. We came across a paper by Jensen and Hammer, who designed a series of 37 constitutive promoters and characterised their activity in both E. coli and L. lactis using a beta galactosidase assay. They provided an image of aligned sequences juxtaposed with their activity in both species, and this made us wonder whether we could selectively alter certain parts of these sequences to optimise their activity for our purposes. We realised this would mean designing a more active constitutive promoter for our agrC and agrA sensing components, as we want these to be expressed all the time and in large amounts. However, this tool could be used by other iGEM teams who may want a promoter associated with a lower constitutive expression to keep readthrough expression levels at a low level (for more information, see our Collaborations Page)
How does our model work?
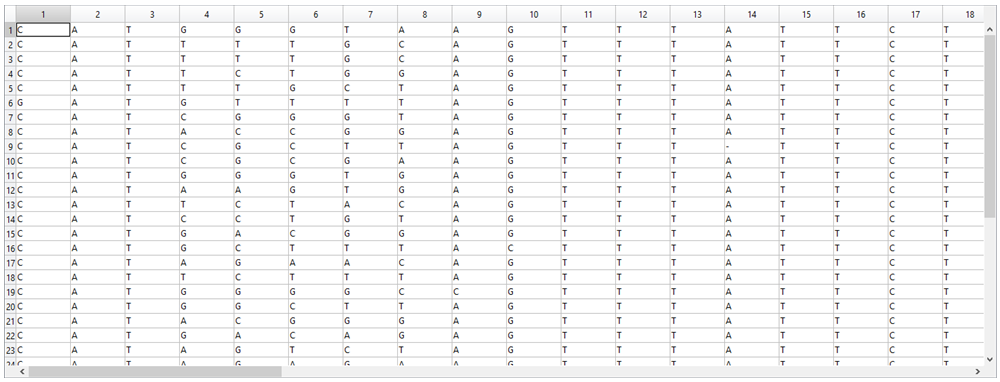
1. Each sequence was hand-typed into an Excel file and, for ease of comparison, the sequences were aligned and if there was a deletion, it was indicated with “-“.
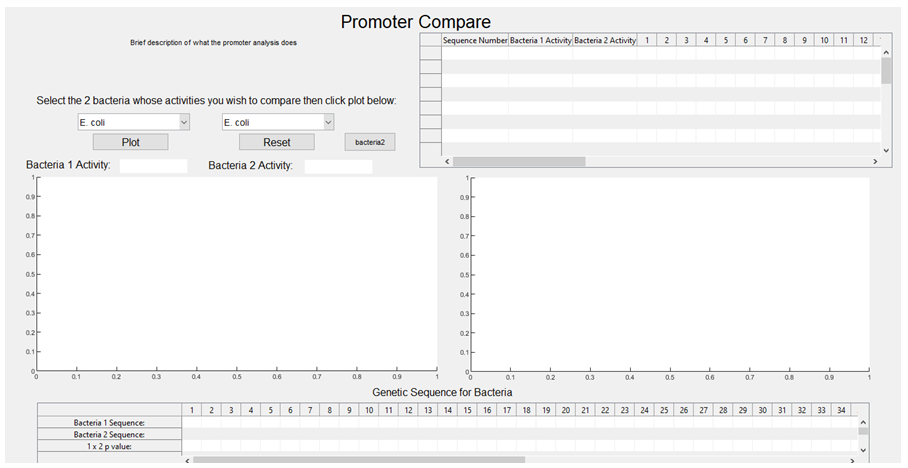
2. Once the program is started in Matlab, the first pop up window you see is this:
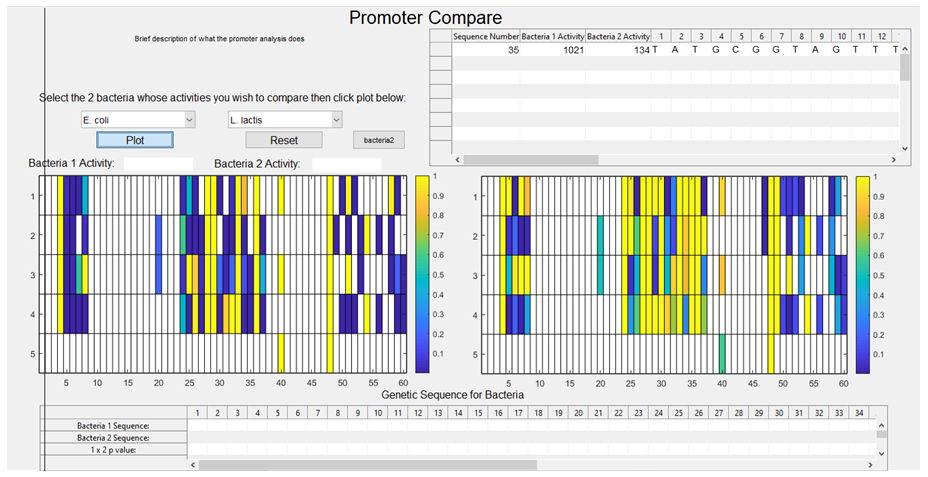
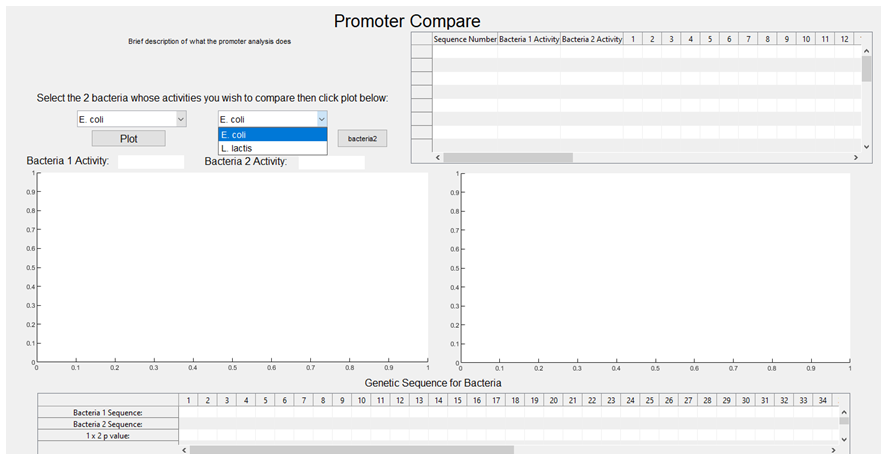
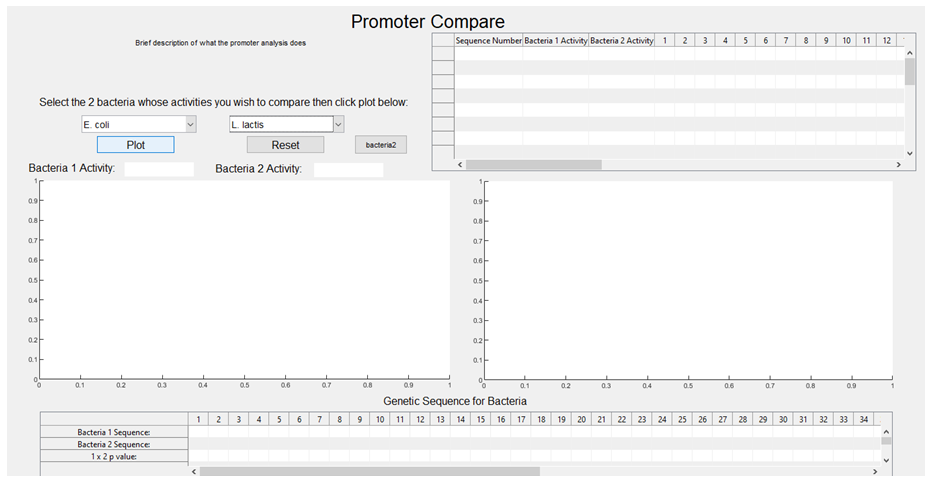
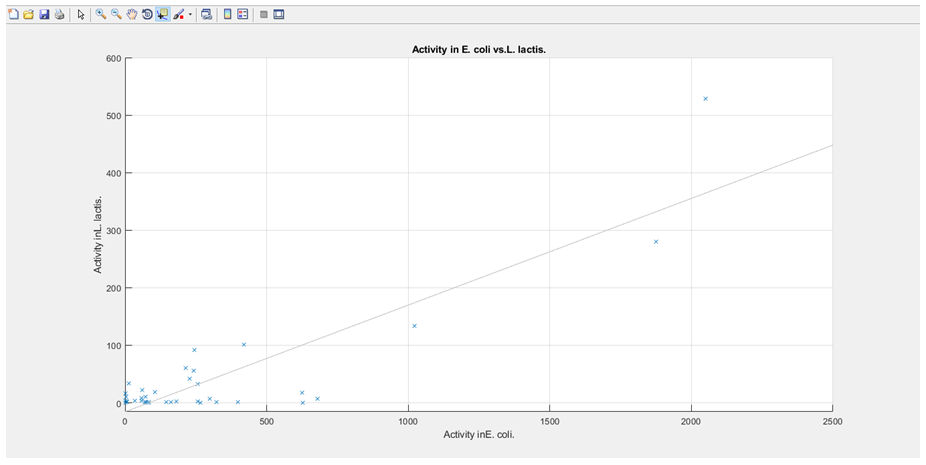
3. The activities associated with each sequence are plotted against each other, with E.coli on the x-axis and L. lactis on the y-axis (the graph is then stored and will pop up upon the user selecting E. coli and L. lactis from the GUI dropdown boxes, with a regression line also plotted).
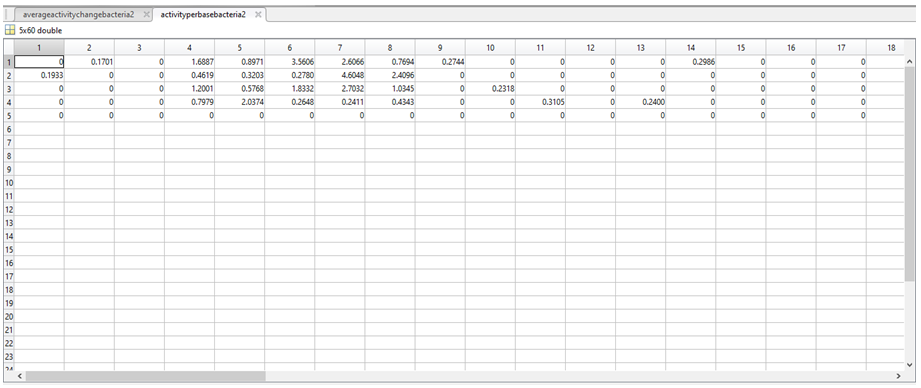
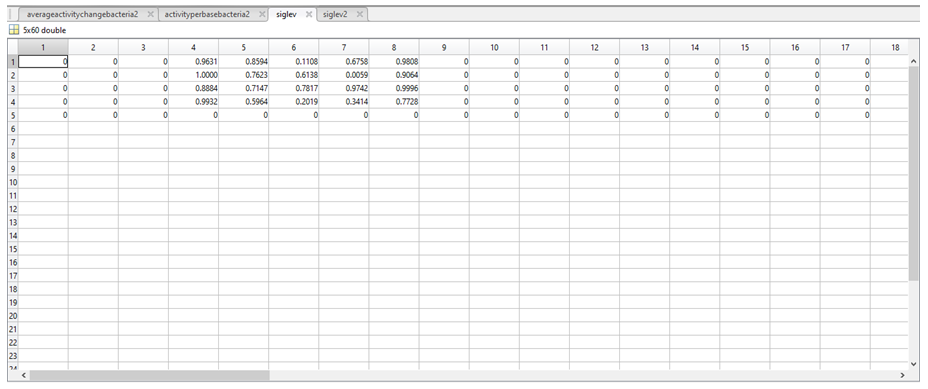
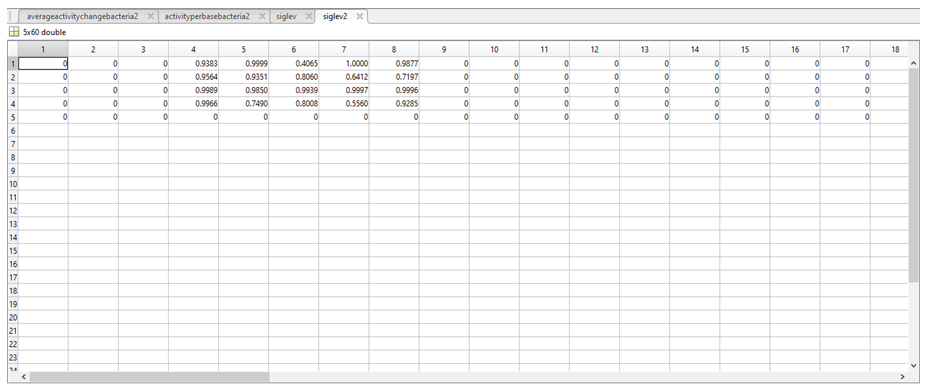
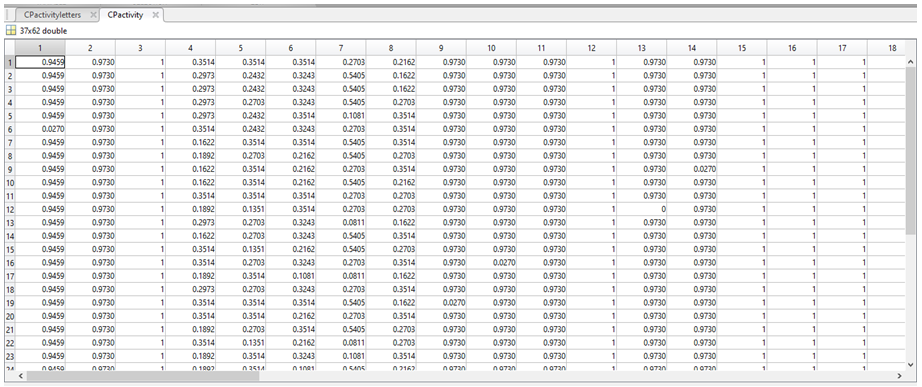
4. We determined the frequency of each nucleotide in a particular column (e.g.: in column 1 94.59% of nucleotides were a “C”, 2.7% were “G”, 2.7% were a “T”, and there were no “A” or “-“).
5. The end result is a large table comparing the frequencies of each nucleotide in a particular position (column) across the 37 sequences, which we called CPactivity.
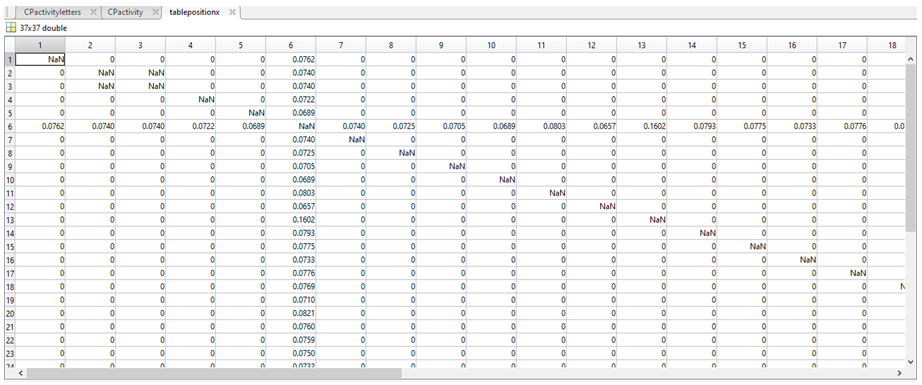
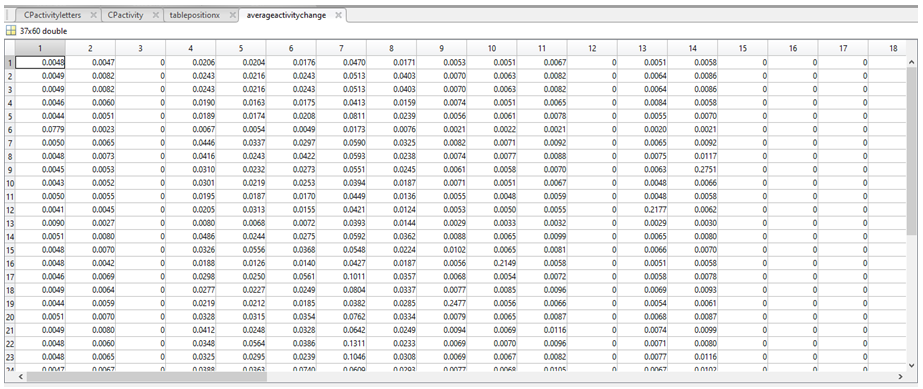
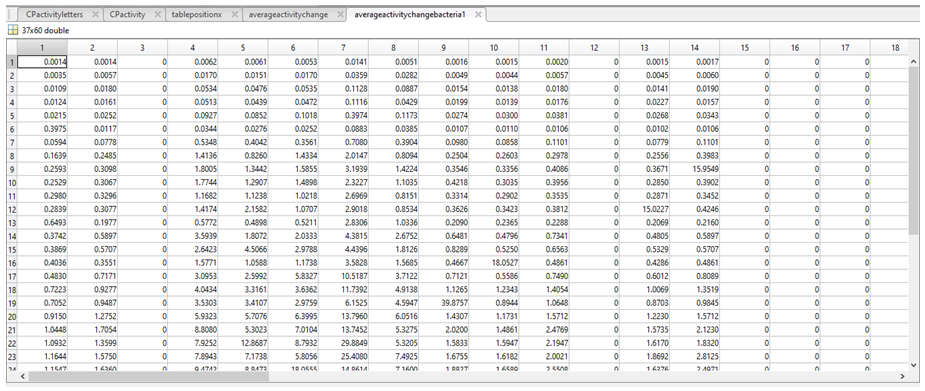
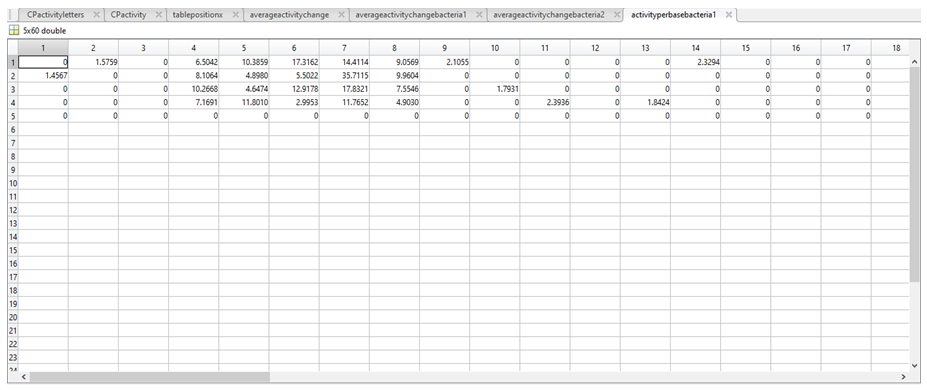
6. We then used the following equation:
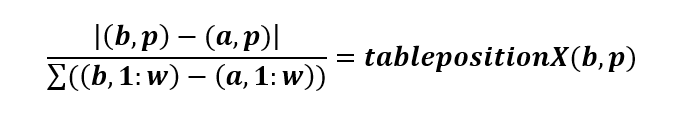
(b, p) = coordinate 1, where b can be any value row index between 1 and 37 (i.e. the total number of sequences) and p is any column index between 1 and 60
(a, p) = coordinate 2, where a can be any value row index between 1 and 37 (i.e. the total number of sequences) and does not have to be equal to b; however, if b=a, a NaN value will be generated.
(b, 1:w) = the sum of the values in row b
(a, 1:w) = the sum of the values in row a
Note: coordinates are written as (row, column)